深入分析京东的云计算PaaS平台所利用的技术
京东PaaS平台的主要服务对象是两类人群,一类是个人开发者,二类是京东的ISV。在数据开放平台日益成熟的背景下,他们都希望以最低的成本,方便地部署自己的应用,提高生产力。而京东PaaS平台正是以满足开发者和ISV的这一需求而开发的。
京东PaaS平台的核心是JAE(Jingdong App Engine),它以Cloud Foundry为内核,之所以选择Cloud Foundry,是因为Cloud Foundry是最早开源,在社区里最成熟、最活跃的基础PaaS平台。为了给开发者提供更加便捷的服务,JAE将基础服务云化,接入各种应用组件服务,诸如高可用MySQL服务、Redis缓存集群服务、以及消息队列等;此外,它结合应用开发工具,为开发者提供了类github的代码托管服务,云测试和Java工程云端编译,以及资源统计信息,让开发者可以更专注于自己的代码业务。再者,JAE对托管在平台上的应用进行健康监控,支持查看应用日志,提供其它安全服务。让开发者只需关心自己应用代码,而其它一切事情,都由JAE为其提供,极大地提高了开发者的效率,降低了开发成本。下图描述了JAE与PaaS平台用户及其他相关服务之间的关系。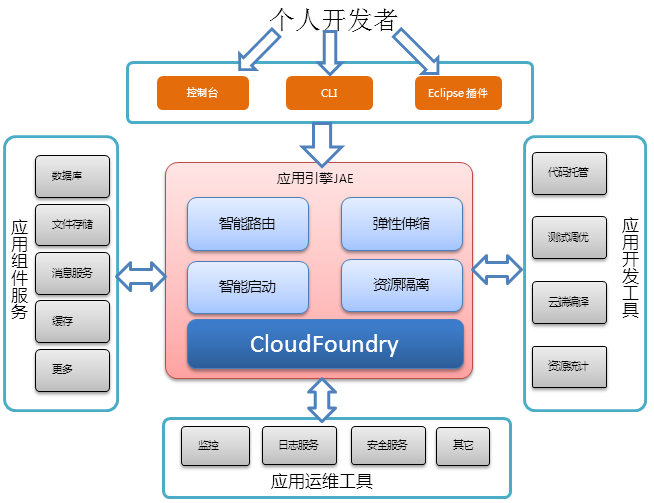
JAE还根据京东PaaS平台的需求,做了许多有针对性的功能扩展。本文主要就JAE的核心技术点展开讨论,JAE的其它基础服务将参见其官方网站:
智能路由(Load Balance)
我们知道,Cloud Foundry支持设置应用的实例个数。但是,当并发量增大时,请求(Request)是否能够均匀地分配给后端的实例?针对多实例的应用,Cloud Foundry采用随机策略地响应客户端的请求,并不能公平有效地利用实例资源,在并发量峰值时候,存在发生雪崩的可能性。为解决这一潜在问题,JAE借鉴了nginx的路由策略,采用权重(weight)算法,负载越小的实例越有机会响应请求。那么,我们需要进一步解决的问题是:如何计算实例的负载,以及如何在接收请求之后对其进行分流?
下图是JAE的模块关系图:
所有请求首先到达router模块,router保存所有实例的路由信息(即实例的ip和port),并由它决定由哪个实例来响应请求。每个实例的ip和port信息都是dea模块经过nats消息总线转发给router的,其实现原理是:dea将自身服务器上的所有实例信息发给nats,router订阅了这则消息,收到之后保存在路由表中,通过过期失效机制来定期获得最新的实例信息。
为使router获得各实例的负载信息。我们对dea模块进行改造,在其每次向nats发送消息的时候,将实例在这一时刻的负载信息也“捎带”上。dea模块收集dea服务器本身以及所有实例的CPU使用率、内存使用率、I/O等原始信息,一并发送给router。router决定如何从这些原始数据中计算出负载值。
至于采用何种算法来计算负载,这是router自身的职责范围,我们采用了类似下面的算法:
实例真实负载 = ( vm负载 * 30% + 实例负载 * 70% ) * 100% vm负载 = CPU 已使用% * 30% + Mem 已使用% * 30% 实例负载 = CPU 已使用% * 30% + Mem 已使用% * 30%
在上述算法中,我们在计算实例的负载值时考虑了dea的因素,其原因在于dea实际就是服务器(虚拟机),而实例运行在dea上的各个进程之上。如果某个dea的负载很高,而其上的某个实例的负载却很低,此时router不一定会将请求交给这个实例。所有算法都要考虑dea的感受。
每个应用实例的负载值计算出来之后,如何决定哪个实例可以优先响应客户端请求,JAE提供了以下几个均衡策略:
从下面这段代码可以看出,Router使用了weight策略。
有状态的(stateful)请求不经过智能路由的处理。比如,当存在session时,第一次请求之后,服务器将响应该请求的实例信息回写至客户端的cookie中,当router收到该客户端的下一次请求时,会将其转发给同一实例。
也许有人会问,这样做是否会影响请求的响应时间?答案是肯定的,但是影响很小,因为该算法是纯数值计算,效率非常高。目前的算法只考虑了几个常用的因素,还存在优化的空间,比如增加负载的因素,如I/O,实例带宽使用情况等。
弹性伸缩(Auto-scaling)
接续上一话题,当并发量持续增大,通过智能路由可以均衡所有实例的负载,但如何应对实例的负载持续升高,面临应用随时不可用的情况?只有增加实例!虽然,我们可以通过JAE控制界面轻松地为一个应用增加或减少实例数(只要在资源满足的情况下)。但这种纯手动的方法显然不可取,JAE将此过程自动化,所采用的就是弹性伸缩机制。
惯用的方法就是定义伸缩规则,下面这是JAE管理页面的规则设置:
规则是用户层面的全局定义,每个用户可以创建多个规则,具体的应用绑定规则之后才能生效。
规则的正确执行依赖于“过去几分钟内,应用的平均请求次数”这一指标。我们通过实时统计来获取这一指标,其实现流程图如下图所示:
所有router服务器都安装了agent,flume集群实时收集router的nginx访问日志,保存在redis中并定期进行清理,同时将分析结果保存在同一redis集群中,规则引擎从redis中取得数据,与此应用的规则对比,判断是否触发规则,之后调用cloudcontroller restful api 来扩展或缩减实例数。
将原始日志以及分析结果传送给云日志和云监控模块,为应用提供相应的功能。 如dashboard管理页面上的应用日志查看,检索;应用PV、UV监控趋势图等。
智能启动(Auto-loading)
如果有80%的应用不活跃,却一直占用着资源,就会造成极大浪费。智能启动的含义是当某个应用在一段时间内未收到请求,则将应用暂时休眠,等下一次请求到达时,立即启动此应用。长时间没有请求的应用,再次访问的时候,会有秒级的加载延迟。
如图所示,智能启动也用到了访问日志的计算结果,计算的是每个应用在统计周期内的访问次数,同样保存在Redis集群中。智能启动模块从CCDB中过滤取得待处理的应用列表,依次获取Redis关于周期内应用的总访问次数,如发现为零则先调用cc restful api 停止应用,再将CCDB中的此应用标识为sleep状态,同时通知Router更新路由表信息,这样路由表中既有所有正在运行的应用实例信息,又有sleep状态的应用信息。当Router接收到下一个访问的时候,首先从路由表是查找对应的实例信息,发现此应用处于sleep状态,就会激活此应用,并且立刻返回给客户端一个正在加载页面。这样再刷新页面,就可以正常访问应用了。下表从nats message来说明模块间的交互:
资源隔离与访问控制
资源隔离是Cloud Foundry的精髓,应用在JAE上除了各种功能方便开发外,最重要的还是“安全感”了,资源隔离即应用之间的资源相互隔离不干扰,访问控制是指在JAE内部,应用之间不能通过任何方式相互访问,不能操作其它应用的代码,但可以通过HTTP方式访问其它应用。JAE在整个过程也做了一些尝试,这里分享一下。
Cloud Foundry用warden来实现资源隔离与访问控制的,但是JAE的第一个版资源隔离策略使用了vcap dev,当时没有warden。在当时的背景下,Cloud Foundry官网还未迁移至v2版、业内的成功应用也比较少, JAE采取稳中求进的方案,即在vcap dev的基础上,借鉴了warden思路,以此来实现资源隔离和访问控制。下面,我们将详细介绍JAE的第一版资源隔离实现方法,该方法部署起来所需的资源比较灵活,既支持单机部署也支持多机部署,对个人开发者有很好的借鉴参考。
如上图所示,JAE第一版资源隔离与访问控制的实现方式是 vcap safemode +cgroup+quota+ACL。首先,vcap safemode提供了访问控制的功能,安全模式为dea服务器创建了n个用户,默认是32个用户,vap-user-11至vap-user-32,属于vcap-dea用户组,启动一个应用实例就为其分配一个用户,并将代码目录的拥有者设置为此用户,实例停止则回收用户。这样可以简单地保证应用间的访问控制,不同应用(不同用户)相互不可访问。
vcap safemode只是设置了应用目录的权限,限制了目录间的访问,但是仍然可以看到或操作大部分系统命令,系统文件,如ls, mkdir, /usr/bin,/etc/init.d/,这是很危险的。JAE通过linux的ACL(access control list)将大部分的系统命令都禁掉了,这有点杀敌一千自损八百的味道,很多应用是需要调用系统命令的。ACL的具体做法是限制了用户组vcap-dea对绝大多数系统命令的查看、操作权限:
JAE用safemode+ACL实现了某种意义上的访问控制。为什么说是某种意义上的?它虽然提供了一些功能,但是没有Namespace的概念,在特定的Namespace中,PID、IPC、Network都是全局性的,每个Namesapce里面的资源对其他Namesapce都是透明的,而safemode+ACL则是一种共享的方案。Namespace问题也是后来JAE升级的主要原因。
其次说到资源隔离,一个应用用到的系统资源大概有内存、CPU、磁盘和带宽等。JAE借鉴warden的方案,使用linux内核自带的cgroup 和quota来解决内存、CPU、磁盘的隔离问题。
下面,借此机会介绍warden的实现细节。
warden实现原理
cgroup(Control Group)是Linux内核的功能,简单的说,它是对进程进行分组,然后以组为单位进行资源调试与分配,其结构是树形结构,每个root管理着自己下面的所有分支,而且分支共享着root的资源。由各个子系统控制与监控这些组群。cgroup的子系统有: CPU、CPUset、CPUacct、memory、devices、blkio、net-cls、freezer,不同的linux内核版本,提供的子功能有所差异。
cgroup的系统目录位于 /sys/fs/cgroup,JAE宿主机是ubuntu12.04 LTS,默认的有以下几个子系统:CPU、CPUacct、devices、freezer、memory
当dea启动的时候,会重新初始化cgroup,重新mount子系统。
将cgroup系统安装在/tmp/container/cgroup下,mount了4个子系统。当部署一个应用时,/tmp/container/cgroup/memory目录生成此应用的进程节点,命名为#{instance_name}-#{instance_index}-#{instance_id},即“应用名-应用实例号-实例id”,将应用的内存配额写入memory.limit_in_bytes以及memory.memsw.limit_in_bytes。限制了可使用的最大内存以及swap值。
接着将实例的进程ID写入各个子系统的tasks文件中,注意到每个子模块的notify_on_release都设置为1,这是告诉cgroup,如果应用消耗的资源超过限制,就kill掉进程。Warden中写了个OomNotifier服务来监控内存的消耗情况,然后做具体操作。个人觉得太复杂,可能OomNotifier有更“温柔”的处理方法或有更多逻辑处理。但是目前来看,OomNotifier 只是做了kill操作。
JAE为什么对内存设置了配额,而对CPU子系统没有设置呢?因为在JAE环境中,应用主要以内存消耗为主,而且CPU如果要设置配额,只能设置占用时间的比例,在逻辑上就无法更直观地为某个应用分配CPU资源,所以就采用了“平均分配”的原则。如果一台虚拟机上只有一个应用实例,那么此应用实例可以“独享”所以CPU资源,如果有两个应用实例,各自最多只能用50%,以此类推。 CPU的使用率是过去一段时间内,应用实例占用的CPU时间/总时间。
接下来说到磁盘配额,JAE使用了linux内核的Quota。Quota可以对某一分区下指定用户或用户组进行磁盘限额。限额不是针对用户主目录,而是针对这个分区下的用户或用户组。Quota通过限制用户的blocks或者inodes超到限额的作用。
Quota的初始化同样发生在启动dea时,在此之前,要先安装quota,并指定要进行quota管理的分区,这里用$1传参。
当部署一个应用实例时,quota设置磁盘配额。上面vcap safemode提到,每个实例都分配一个用户,而quota就是对此用户的配额管理。Quota管理blocks和inodes有hard和soft两个临界点,超过soft值,可允许继续使用,若超过hard值,就不再允许写入操作了。
Block和inode都给了512M的缓冲值。因为实例停止或删除后,用户会回收,所以此用户的quota需要重置。Repquota -auvs 查看磁盘使用情况:
通过使用cgroup、quota、ACL,JAE间接地实现了warden的部分功能,上面提到的Namespace问题,由于ACL的限制,应用无法使用系统命令,但是从应用的角度,实例应该跑在一个运行环境完备的操作系统(container)上,可以做任何事情,而不是有各种限制。
JAE第一版于2013 年6月上线,维持了两个月之后,我们越来越意识到Namespace的重要性。此后,我们又花了一个月的时间,在Cloud Foundry v2的基础上,将JAE第一版的功能全部迁移过来,用warden来实现访问控制与资源隔离,JAE第二版于2013年9月中旬上线。
在升级的过程中,我们发现了Cloud Foundry v1与v2的诸多不兼容问题。譬如,v2引入了organization、spaces、domain的概念;router用go重写,去掉了nginx,导致flume收集nginx日志方案重新设计;v2的cloudcontroller restful api的变化,dashboard几乎是重写的;运行在warden内部的应用,没有权限直接读取日志文件;在v1上运行的应用,大部分不能运行在v2上,为此我们做了个转化部署的自动化工具,将v1上的应用迁移至v2上。 添加了php和python的buildpack,并做了定制。
在JAE的部署方面,由于底层的openstack环境做了较多改进,接口也发生了一些变化,Bosh原生的openstack CPI可能满足不了要求,我们决定放弃Bosh,采用更简单的capistrano来做集群部署,JAE集群数目则通过手动去扩展。
总结
虽然京东云擎正处于发展的初级阶段,但是我们坚信未来有充分的发展空间,我们计划后续要做的工作有:
用户自定义域名的绑定;
智能路由和智能启动,将负载计算多元化,更能体现后端实例的真实负载;
持久化的分布式文件系统,保证应用实例保持在本地的数据不会丢失;
智能启动或重启停止应用时使用snapshot,保证现场环境的完整性;
.nats cluster,避免nats单点;


