美团网站的数据搜索排序解决方案精华分享
一、线上篇
随着业务的发展,美团的商家和团购数正在飞速增长。这一背景下,搜索排序的重要性显得更加突出:排序的优化能帮助用户更便捷地找到满足其需求的商家和团购,改进用户体验,提升转化效果。
和传统网页搜索问题相比,美团的搜索排序有自身的特点——90%的交易发生在移动端。一方面,这对排序的个性化提出了更高的要求,例如在“火锅”查询下,北京五道口的火锅店A,对在五道口的用户U1来说是好的结果,对在望京的用户U2来讲不一定是好的结果;另一方面,我们由此积累了用户在客户端上丰富准确的行为,经分析获得用户的地理位置、品类和价格等偏好,进而指导个性化排序。
针对美团的O2O业务特点,我们实现了一套搜索排序技术方案,相比规则排序有百分之几十的提升。基于这一方案,我们又抽象了一套通用的O2O排序解决方案,只需1-2天就可以快速地部署到其他产品和子行业中,目前在热词、Suggestion、酒店、KTV等多个产品和子行业中应用。
我们将按线上和线下两部分分别介绍这一通用O2O排序解决方案,本文是线上篇,主要介绍在线服务框架、特征加载、在线预估等模块,下篇将会着重介绍离线流程。
排序系统
为了快速有效的进行搜索算法的迭代,排序系统设计上支持灵活的A/B测试,满足准确效果追踪的需求。
美团搜索排序系统如上图所示,主要包括离线数据处理、线上服务和在线数据处理三个模块。
离线数据处理
HDFS/Hive上存储了搜索展示、点击、下单和支付等日志。离线数据流程按天调度多个Map Reduce任务分析日志,相关任务包括:
离线特征挖掘
产出Deal(团购单)/POI(商家)、用户和Query等维度的特征供排序模型使用。
数据清洗标注 & 模型训练
数据清洗去掉爬虫、作弊等引入的脏数据;清洗完的数据经过标注后用作模型训练。
效果报表生成
统计生成算法效果指标,指导排序改进。
特征监控
特征作为排序模型的输入是排序系统的基础。特征的错误异常变动会直接影响排序的效果。特征监控主要监控特征覆盖率和取值分布,帮我们及时发现相关问题。
在线数据处理
和离线流程相对应,在线流程通过Storm/Spark Streaming等工具对实时日志流进行分析处理,产出实时特征、实时报表和监控数据,更新在线排序模型。
在线服务(Rank Service)
Rank Service接到搜索请求后,会调用召回服务获取候选POI/Deal集合,根据A/B测试配置为用户分配排序策略/模型,应用策略/模型对候选集合进行排序。
下图是Rank Service内部的排序流程。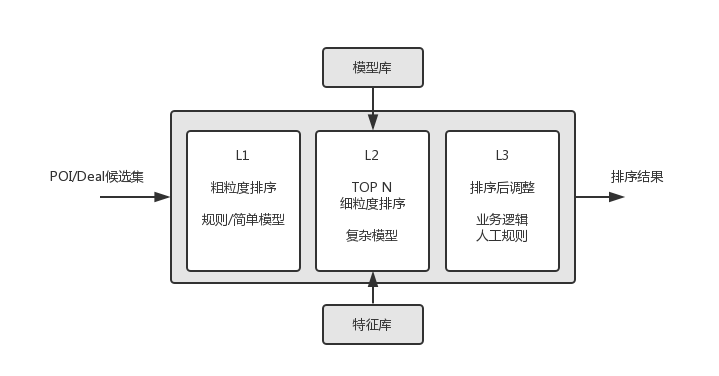
L1 粗粒度排序(快速)
使用较少的特征、简单的模型或规则对候选集进行粗粒度排序。
L2 细粒度排序(较慢)
对L1排序结果的前N个进行细粒度排序。这一层会从特征库加载特征(通过FeatureLoader),应用模型(A/B测试配置分配)进行排序。
L3 业务规则干预
在L2排序的基础上,应用业务规则/人工干预对排序进行适当调整。
Rank Service会将展示日志记录到日志收集系统,供在线/离线处理。
A/B测试
A/B测试的流量切分是在Rank Server端完成的。我们根据UUID(用户标识)将流量切分为多个桶(Bucket),每个桶对应一种排序策略,桶内流量将使用相应的策略进行排序。使用UUID进行流量切分,是为了保证用户体验的一致性。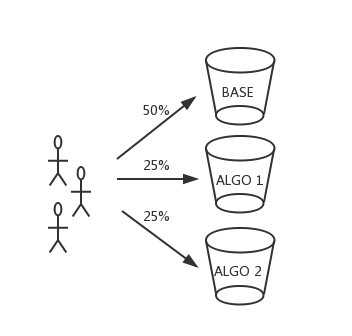
下面是A/B测试配置的一个简单示例。
"search": {
"NumberOfBuckets": 100,
"DefaultStrategy": "Base",
"Segments": [
{
"BeginBucket": 0,
"EndBucket": 24,
"WhiteList": [123],
"Strategy": "Algo-1"
},
{
"BeginBucket": 25,
"EndBucket": 49,
"WhiteList": [],
"Strategy": "Algo-2"
}
]
}
}
对于不合法的UUID,每次请求会随机分配一个桶,以保证效果对比不受影响。白名单(White List)机制能保证配置用户使用给定的策略,以辅助相关的测试。
除了A/B测试之外,我们还应用了Interleaving[7]方法,用于比较两种排序算法。相较于A/B测试,Interleaving方法对排序算法更灵敏,能通过更少的样本来比较两种排序算法之间的优劣。Interleaving方法使用较小流量帮助我们快速淘汰较差算法,提高策略迭代效率。
特征加载
搜索排序服务涉及多种类型的特征,特征获取和计算是Rank Service响应速度的瓶颈。我们设计了FeatureLoader模块,根据特征依赖关系,并行地获取和计算特征,有效地减少了特征加载时间。实际业务中,并行特征加载平均响应时间比串行特征加载快约20毫秒。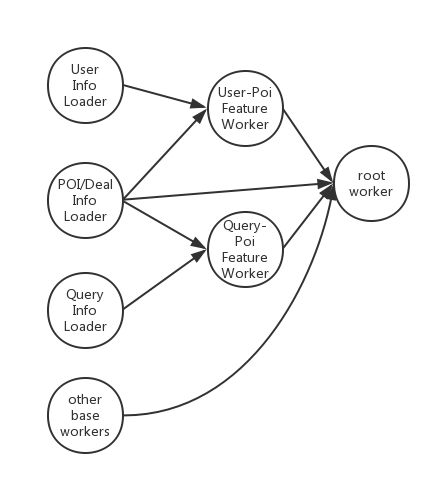
FeatureLoader的实现中我们使用了Akka[8]。如上图所示,特征获取和计算的被抽象和封装为了若干个Akka actor,由Akka调度、并行执行。
特征和模型
美团从2013年9月开始在搜索排序上应用机器学习方法(Learning to Rank),并且取得很大的收益。这得益于准确的数据标注:用户的点击下单支付等行为能有效地反映其偏好。通过在特征挖掘和模型优化两方面的工作,我们不断地优化搜索排序。下面将介绍我们在特征使用、数据标注、排序算法、Position Bias处理和冷启动问题缓解等方面的工作。
特征
从美团业务出发,特征选取着眼于用户、Query、Deal/POI和搜索上下文四个维度。
用户维度
包括挖掘得到的品类偏好、消费水平和地理位置等。
Query维度
包括Query长度、历史点击率、转化率和类型(商家词/品类词/地标词)等。
Deal/POI维度
包括Deal/POI销量、价格、评价、折扣率、品类和历史转化率等。
上下文维度
包括时间、搜索入口等。
此外,有的特征来自于几个维度之间的相互关系:用户对Deal/POI的点击和下单等行为、用户与POI的距离等是决定排序的重要因素;Query和Deal/POI的文本相关性和语义相关性是模型的关键特征。
模型
Learning to Rank应用中,我们主要采用了Pointwise方法。采用用户的点击、下单和支付等行为来进行正样本的标注。从统计上看,点击、下单和支付等行为分别对应了该样本对用户需求的不同的匹配程度,因此对应的样本会被当做正样本,且赋予不断增大的权重。
线上运行着多种不同类型模型,主要包括:
Gradient boosting decision/regression tree(GBDT/GBRT)
GBDT是LTR中应用较多的非线性模型。我们开发了基于Spark的GBDT工具,树拟合梯度的时候运用了并行方法,缩短训练时间。GBDT的树被设计为三叉树,作为一种处理特征缺失的方法。
选择不同的损失函数,boosting tree方法可以处理回归问题和分类问题。应用中,我们选用了效果更好的logistic likelihood loss,将问题建模为二分类问题。
Logistic Regression(LR)
参考Facebook的paper[3],我们利用GBDT进行部分LR特征的构建。用FTRL算法来在线训练LR模型。
对模型的评估分为离线和线上两部分。离线部分我们通过AUC(Area Under the ROC Curve)和MAP(Mean Average Precision)来评价模型,线上则通过A/B测试来检验模型的实际效果,两项手段支撑着算法不断的迭代优化。
冷启动
在我们的搜索排序系统中,冷启动问题表现为当新的商家、新的团购单录入或新的用户使用美团时,我们没有足够的数据用来推测用户对产品的喜好。商家冷启动是主要问题,我们通过两方面手段来进行缓解。一方面,在模型中引入了文本相关性、品类相似度、距离和品类属性等特征,确保在没有足够展示和反馈的前提下能较为准确地预测;另一方面,我们引入了Explore&Exploit机制,对新商家和团单给予适度的曝光机会,以收集反馈数据并改善预测。
Position Bias
在手机端,搜索结果的展现形式是列表页,结果的展示位置会对用户行为产生很大的影响。在特征挖掘和训练数据标注当中,我们考虑了展示位置因素引入的偏差。例如CTR(click-through-rate)的统计中,我们基于Examination Model,去除展示位置带来的影响。
线上篇总结
线上篇主要介绍了美团搜索排序系统线上部分的结构、算法和主要模块。在后续文章里,我们会着重介绍排序系统离线部分的工作。
一个完善的线上线下系统是排序优化得以持续进行的基础。基于业务对数据和模型上的不断挖掘是排序持续改善的动力。我们仍在探索。
二、线下篇
针对美团90%的交易发生在移动端的业务特点,我们实现了一套适用于O2O业务的搜索排序技术方案,已在许多产品和子行业中得到应用。在之前的线上篇中,我们已经介绍了服务的框架、排序算法等。本文为线下篇,主要讲述数据清洗、特征矩阵、监控系统、模型训练和效果评估等模块。
数据清洗
数据清洗的主要工作是为离线模型训练准备标注数据,同时洗掉不合法数据。数据清洗的数据源主要有团购的曝光、点击和下单。
整个数据清洗的流程如下:
序列化
曝光、点击和下单数据从Hive表中读取,采用schema的处理方式,可以直接根据日志字段名来抽取相应的字段,不受日志字段增加或者减少的影响。
曝光日志存储了一次用户行为的详细信息,包括城市、地理位置、筛选条件及一些行为特征;点击日志主要记录了用户点击的POIID、点击时间;下单日志记录了用户下单的POIID、下单时间和下单的金额。数据清洗模块根据配置文件从数据源中抽取需要的字段,进行序列化(Serialization)之后存储在HDFS上。
序列化的过程中,如果日志字段不合法或者单一用户曝光、点击或下单超出设定的阈值,相关日志都会被清洗掉,避免数据对模型训练造成影响。
数据标注
数据序列化之后在HDFS上保存三份文本文件,分别是曝光(Impression)、点击(Click)和下单(Order)。数据标注模块根据globalid(一次搜索的全局唯一标示,类似于sessionid)和相应的团购id为key,将曝光、点击和下单关联起来,最终生成一份标注好是否被点击、下单、支付的标注数据。同时这份标注数据携带了本次展现的详细特征信息。
数据标注通过一次Map/Reduce来完成。
Map阶段:Map的输入为曝光、点击和下单三种HDFS数据。 用三个Mapper分别处理三种日志。数据分发的key为globalid。其中,如果点击和下单数据中的globalid字段为空(""),则丢弃该条日志(因为globalid为空无法和曝光日志join,会出现误标注)。
Reduce阶段:Reduce接收的key为globalid, values为具有相同globalid的曝光、点击、下单数据List,遍历该List, 如果
日志类型为曝光日志,则标记该globalid对应的曝光日志存在(imp_exist=true)。
日志类型为点击日志,则将曝光日志的clicked字段置为1。
日志类型为下单日志,则将曝光日志的ordered字段置为1。
日志类型为下单日志,如果pay_account字段>0, 则将曝光日志的paid字段置为1。
遍历List之后,如果imp_exist == true, 则将标注好的数据写入HDFS, 否则丢弃。
数据标注的流程图如下:
特征矩阵
特征矩阵的作用是提供丰富的特征集合,以方便在线和离线特征调研使用。
特征矩阵的生成
特征矩阵的生成框架为:
下面我们来详细说明一下流程。
基础特征按来源可分为三部分:
1、Hive表:有一些基础特征存储在Hive标注,如POI的名字、品类、团购数等。
2、离线计算:一些特征需要积累一段时间才能统计,如POI的点击率、销量等,这部分通过积累历史数据,然后经过Map/Reduce处理得到。
3、HDFS:特征矩阵可能融合第三方服务的特征,一般第三方服务将产生的特征按照约定的格式存储在HDFS上。
数据源统一格式为: poiid/dealid/bizareaid '\t' name1:value1'\t' name2:value2...
特征合并模块,将所有来源合并为一个大文件,通过feature conf配置的特征和特征顺序,将特征序列化,然后写入Hive表。
特征监控模块每天监控特征的分布等是否异常。 特征矩阵的特征每日更新。
添加新的特征来源,只需要按照约定的格式生成数据源,配置路径,可自动添加。
添加新特征,在feature conf文件末尾添加相应的特征名,特征名字和数据源中的特征name保持一致,最后修改相应的特征Hive表结构。
特征矩阵的使用
特征矩阵的使用框架为: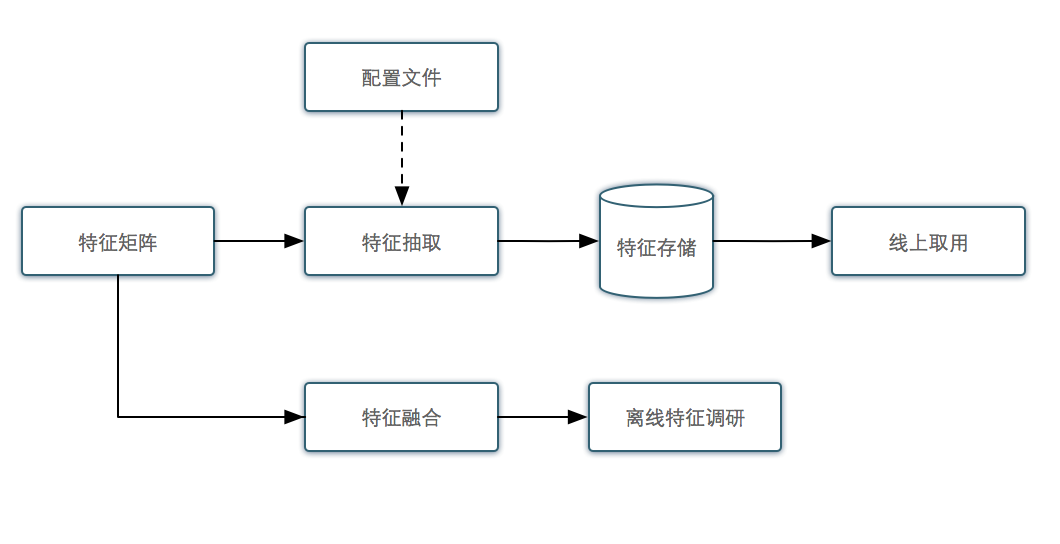
我们来详细说明一下流程。
其中特征矩阵既提供在线的特征仓库,又可提供离线的特征调研。线上服务需要大量的特征来对POI/DEAL质量打分,特征分散会造成服务取用特征很耗时,特征矩阵将特征整合,很好的解决了特征耗时的问题。一般调研一个新特征需要积累一段时间的数据,将特征放入特征矩阵,
然后和已有的数据进行融合,可方便的构造包含新特征的训练数据。下面我们分别来看一下在线、离线和特征融合的流程。
在线使用
在线方面的使用主要是方便特征的获取,将线上需要的特征纳入特征矩阵统一管理,通过配置文件读取特征矩阵的特征,封装成Proto Buffers写入Medis(美团自主构建的Redis集群,支持分布式和容错),通过Medis key批量读取该key对应的特征,减少读取Medis的次数,从而缩减特征获取的时间,提高系统的性能。
特征矩阵在线使用框架如下: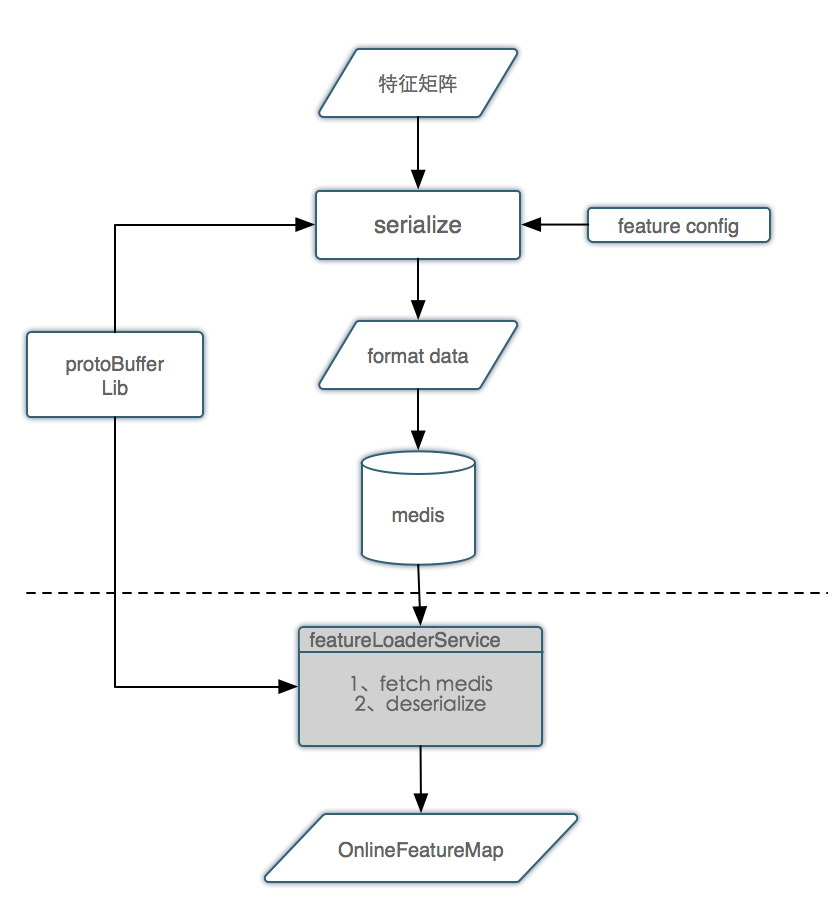
流程说明:
序列化模块通过特征配置文件从特征矩阵抽取需要的特征,调用protoBuffer Lib将特征封装成protoBuffer的格式,写入Medis。
线上通过featureLoader服务从Medis读取数据,然后通过protoBufferLib反序列化数据,取到相应的特征值。
离线使用
离线方面的使用主要是方便调研新特征。如果从线上获取新特征,由于需要积累训练数据,特征调研的周期会变长;而如果将待调研的特征纳入特征矩阵中,可以很方便地通过离线的方法调研特征的有效性,极大的缩短了特征调研的周期,提高开发效率和模型迭代的速度。
特征矩阵离线使用框架如下: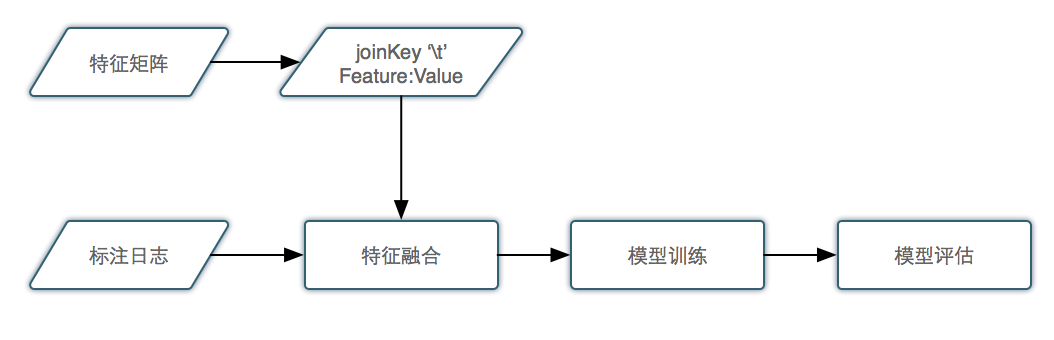
其中,从特征矩阵取出待调研的新特征,格式化为 joinKey '\t' FeatureName:FeatureValue, 例如 12345 '\t' CTR:0.123,joinkey为poiid, 新特征为CTR,特征值为0.123。格式化后的新特征文件和标注好的rerank日志作为输入,经过Map/Reduce处理生成新的标注日志,用于模型训练。
特征融合
特征融合作用于离线特征调研,上篇我们提到数据标准会输出拥有丰富特征的标注日志,特征融合的目的在于将待调研的新特征通过某一个joinkey 合并到在线特征列表中,从而在模型训练中使用该特征。
特征融合的框架:
流程说明: 特征融合模块可以指定任意一个或者多个join key,将离线特征加入在线特征列表。
监控系统
监控系统的目的是确保在线和离线任务的正常运行。监控系统按照作用范围的不同又分为线上监控和离线监控。
线上监控
线上监控主要是监测收集的在线特征日志是否正常,线上特征监控主要检测特征的覆盖度、阈值范围、分布异常三方面。
三方面的监控主要分以下几个场景:
覆盖度:监控特征的数据源是否存在或者有数据丢失。
阈值范围:监控特征的阈值是否符合预期,防止因为生成特征的算法改变或者在线计算方法的不同等因素造成特征的最大值或者最小值发生比较明显的变化,导致特征不可用。
分布异常:监控特征值的分布是否符合预期,主要防止因为获取不到特征,使得特征都使用了默认值,而又没有及时发现,导致线上模型预估出现偏差。分布异常主要用到了卡方距离[3]。
特征覆盖度监控效果图:
下图是用户到POI距离的覆盖度监控。从图中可以直观的看出,该特征的覆盖度约为75%,也即只有75%的用户能得到距离特征,另外25%可能没有开手机定位服务或者得不到POI的坐标。75%的覆盖度是一个比较稳定的指标,如果覆盖度变的很高或者很低都说明我们的系统出现了问题,而我们的监控系统能及时发现这种问题。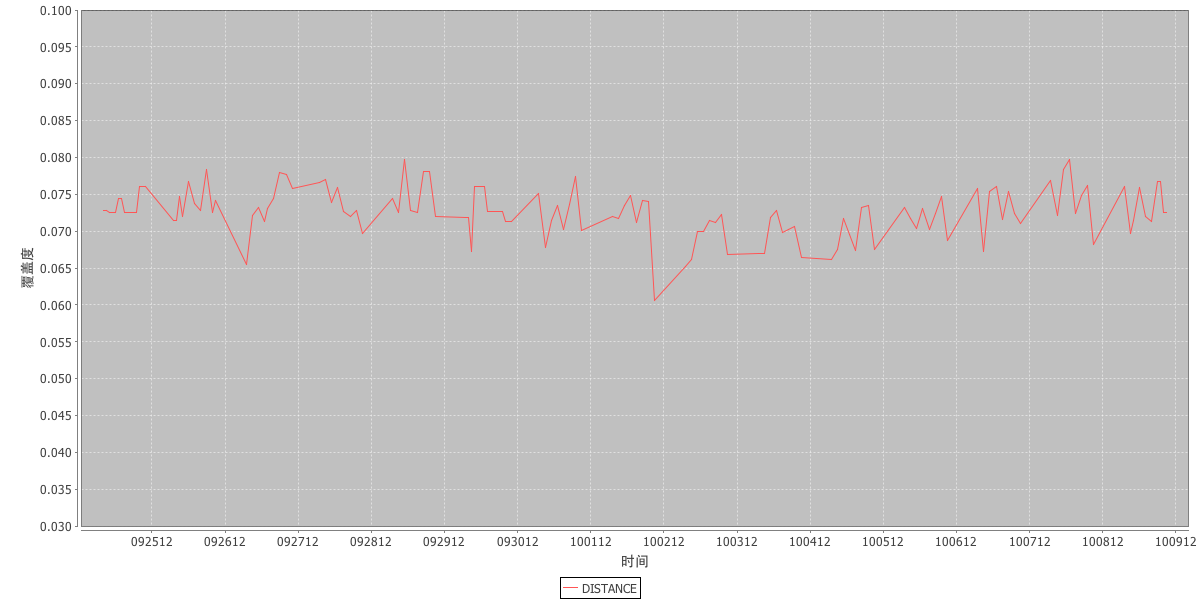
离线监控
离线监控主要检测两方面:1、离线任务是否按时完成及生成的数据是否正确。 2、特征矩阵特征的有效性。
当离线定时任务多达数十个的时候,很难每天去逐个检查每个任务是否如期完成,这时候离线任务监控的重要性就凸显出来。当前离线监控可以根据配置文件,监控需要关注的任务,以及这些任务生成的数据是否正常。如果不正常则发出报警给任务负责人,达到任务失败能够及时处理的目的。
特征矩阵监控的目的与在线特征的监控目的一样,监控指标也相同,所不同的是因为监控数据的获取不同,监控实现也不尽相同,这里不再赘述。
模型调研
模型训练
模型训练框架支持多种模型的训练,将训练数据格式化为模型需要的输入格式。修改模型训练的配置文件,就可以使用该框架训练模型了。
模型训练框架: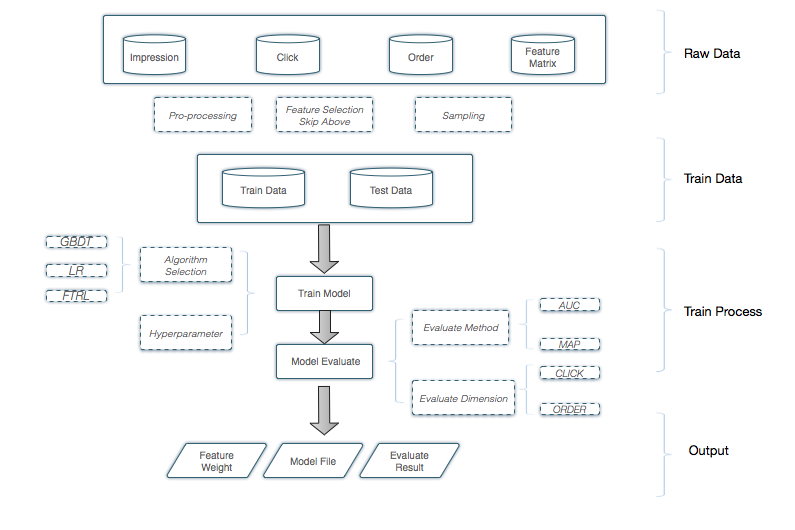
其中,顶层是训练数据和测试数据的输入层,该层是原始训练和测试数据。
中间是模型训练的框架,框架支持多个配置项,包括配置模型算法、相应的参数、数据源的输入及模型的输出等。
底层是多种模型的实现,算法之前相互独立,每种算法封装成独立的jar,提供给模型训练框架使用,目前支持的算法包括GBDT[4]、FTRL[5]。
为了实现模型的快速迭代,模型训练支持在Spark上运行。
效果评估
模型的效果评估主要是对比新模型和老模型的效果,以评估结果来决定是否更新线上模型。
我们的系统支持两种效果指标的评估,一种是AUC[1],另一种是MAP。
MAP(Mean Average Precision)[2]是一种对搜索排序结果好坏评估的指标。
Prec@K 的定义: 设定阈值K,计算排序结果topK的相关度。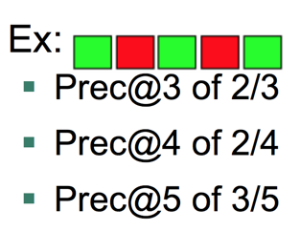
注:绿色表示搜索结果与搜索词相关,红色表示不相关。
AP(Average Precision)的定义: Average Precision = average of Prec@K
AP作为排序好坏的直观理解
灰色表示与搜索相关的结果,在团购中表示被点击的DEAL,从召回结果看Ranking#1要好于Ranking#2,反映在MAP指标上,Ranking#1的MAP值大于Ranking#2的MAP值。
所以可以简单地使用AP值来衡量模型排序的好坏。
MAP的计算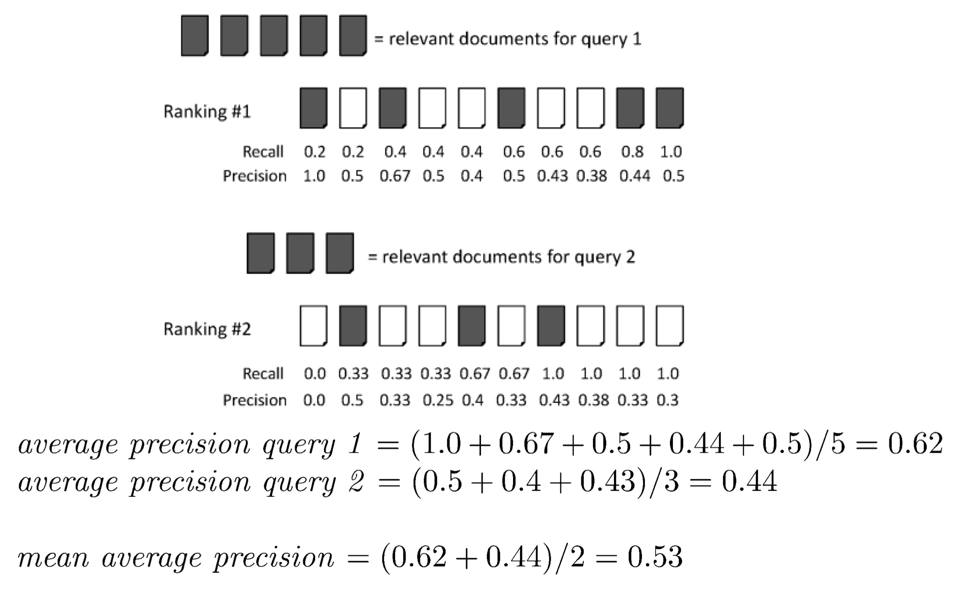
对于多个query的搜索结果,MAP为这些搜索结果AP的均值。
实验结果表明MAP作为排序指标,对模型好坏的评估起到很好的指导作用。
在AUC的近似计算方法中,主要考虑有多少对正负样本组合中正样本的得分大于负样本的得分,与正样本在排序中的具体位置没有绝对的关系。当正负样本的分布变化,如某一小部分正样本得分变大,大部分正样本得分变小,那么最终计算的AUC值可能没有发生变化,但排序的结果却发生了很大变化(大部分用户感兴趣的单子排在了后边)。
因此AUC指标没法直观评估人对排序好坏的感受。


