Keras搭建Efficientdet目标检测平台的实现思路
学习前言
一起来看看Efficientdet的keras实现吧,顺便训练一下自己的数据。

什么是Efficientdet目标检测算法
最近,谷歌大脑 Mingxing Tan、Ruoming Pang 和 Quoc V. Le 提出新架构 EfficientDet,结合 EfficientNet(同样来自该团队)和新提出的 BiFPN,实现新的 SOTA 结果。

源码下载
https://github.com/bubbliiiing/efficientdet-keras
喜欢的可以点个star噢。
Efficientdet实现思路
一、预测部分
1、主干网络介绍

Efficientdet采用Efficientnet作为主干特征提取网络。EfficientNet-B0对应Efficientdet-D0;EfficientNet-B1对应Efficientdet-D1;以此类推。
EfficientNet模型具有很独特的特点,这个特点是参考其它优秀神经网络设计出来的。经典的神经网络特点如下:
1、利用残差神经网络增大神经网络的深度,通过更深的神经网络实现特征提取。
2、改变每一层提取的特征层数,实现更多层的特征提取,得到更多的特征,提升宽度。
3、通过增大输入图片的分辨率也可以使得网络可以学习与表达的东西更加丰富,有利于提高精确度。
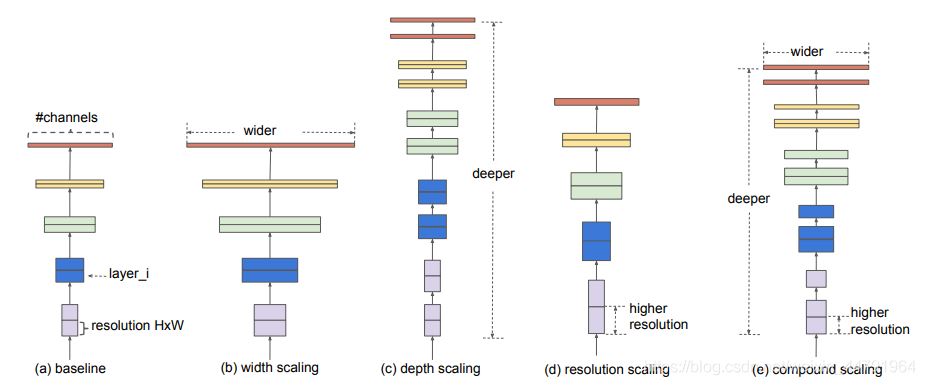
EfficientNet就是将这三个特点结合起来,通过一起缩放baseline模型(MobileNet中就通过缩放α实现缩放模型,不同的α有不同的模型精度,α=1时为baseline模型;ResNet其实也是有一个baseline模型,在baseline的基础上通过改变图片的深度实现不同的模型实现),同时调整深度、宽度、输入图片的分辨率完成一个优秀的网络设计。
在EfficientNet模型中,其使用一组固定的缩放系数统一缩放网络深度、宽度和分辨率。
假设想使用 2N倍的计算资源,我们可以简单的对网络深度扩大αN倍、宽度扩大βN 、图像尺寸扩大γN倍,这里的α,β,γ都是由原来的小模型上做微小的网格搜索决定的常量系数。
如图为EfficientNet的设计思路,从三个方面同时拓充网络的特性。
本博客以Efficientnet-B0和Efficientdet-D0为例,进行Efficientdet的解析。
Efficientnet-B0由1个Stem+16个大Blocks堆叠构成,16个大Blocks可以分为1、2、2、3、3、4、1个Block。Block的通用结构如下,其总体的设计思路是Inverted residuals结构和残差结构,在3x3或者5x5网络结构前利用1x1卷积升维,在3x3或者5x5网络结构后增加了一个关于通道的注意力机制,最后利用1x1卷积降维后增加一个大残差边。

整体结构如下:

最终获得三个有效特征层传入到BIFPN当中进行下一步的操作。
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import json
import math
import string
import collections
import numpy as np
from keras import backend
from six.moves import xrange
from nets.layers import BatchNormalization
from keras import layers
BASE_WEIGHTS_PATH = (
'https://github.com/Callidior/keras-applications/'
'releases/download/efficientnet/')
WEIGHTS_HASHES = {
'efficientnet-b0': ('163292582f1c6eaca8e7dc7b51b01c61'
'5b0dbc0039699b4dcd0b975cc21533dc',
'c1421ad80a9fc67c2cc4000f666aa507'
'89ce39eedb4e06d531b0c593890ccff3'),
'efficientnet-b1': ('d0a71ddf51ef7a0ca425bab32b7fa7f1'
'6043ee598ecee73fc674d9560c8f09b0',
'75de265d03ac52fa74f2f510455ba64f'
'9c7c5fd96dc923cd4bfefa3d680c4b68'),
'efficientnet-b2': ('bb5451507a6418a574534aa76a91b106'
'f6b605f3b5dde0b21055694319853086',
'433b60584fafba1ea3de07443b74cfd3'
'2ce004a012020b07ef69e22ba8669333'),
'efficientnet-b3': ('03f1fba367f070bd2545f081cfa7f3e7'
'6f5e1aa3b6f4db700f00552901e75ab9',
'c5d42eb6cfae8567b418ad3845cfd63a'
'a48b87f1bd5df8658a49375a9f3135c7'),
'efficientnet-b4': ('98852de93f74d9833c8640474b2c698d'
'b45ec60690c75b3bacb1845e907bf94f',
'7942c1407ff1feb34113995864970cd4'
'd9d91ea64877e8d9c38b6c1e0767c411'),
'efficientnet-b5': ('30172f1d45f9b8a41352d4219bf930ee'
'3339025fd26ab314a817ba8918fefc7d',
'9d197bc2bfe29165c10a2af8c2ebc675'
'07f5d70456f09e584c71b822941b1952'),
'efficientnet-b6': ('f5270466747753485a082092ac9939ca'
'a546eb3f09edca6d6fff842cad938720',
'1d0923bb038f2f8060faaf0a0449db4b'
'96549a881747b7c7678724ac79f427ed'),
'efficientnet-b7': ('876a41319980638fa597acbbf956a82d'
'10819531ff2dcb1a52277f10c7aefa1a',
'60b56ff3a8daccc8d96edfd40b204c11'
'3e51748da657afd58034d54d3cec2bac')
}
BlockArgs = collections.namedtuple('BlockArgs', [
'kernel_size', 'num_repeat', 'input_filters', 'output_filters',
'expand_ratio', 'id_skip', 'strides', 'se_ratio'
])
# defaults will be a public argument for namedtuple in Python 3.7
# https://docs.python.org/3/library/collections.html#collections.namedtuple
BlockArgs.__new__.__defaults__ = (None,) * len(BlockArgs._fields)
DEFAULT_BLOCKS_ARGS = [
BlockArgs(kernel_size=3, num_repeat=1, input_filters=32, output_filters=16,
expand_ratio=1, id_skip=True, strides=[1, 1], se_ratio=0.25),
BlockArgs(kernel_size=3, num_repeat=2, input_filters=16, output_filters=24,
expand_ratio=6, id_skip=True, strides=[2, 2], se_ratio=0.25),
BlockArgs(kernel_size=5, num_repeat=2, input_filters=24, output_filters=40,
expand_ratio=6, id_skip=True, strides=[2, 2], se_ratio=0.25),
BlockArgs(kernel_size=3, num_repeat=3, input_filters=40, output_filters=80,
expand_ratio=6, id_skip=True, strides=[2, 2], se_ratio=0.25),
BlockArgs(kernel_size=5, num_repeat=3, input_filters=80, output_filters=112,
expand_ratio=6, id_skip=True, strides=[1, 1], se_ratio=0.25),
BlockArgs(kernel_size=5, num_repeat=4, input_filters=112, output_filters=192,
expand_ratio=6, id_skip=True, strides=[2, 2], se_ratio=0.25),
BlockArgs(kernel_size=3, num_repeat=1, input_filters=192, output_filters=320,
expand_ratio=6, id_skip=True, strides=[1, 1], se_ratio=0.25)
]
CONV_KERNEL_INITIALIZER = {
'class_name': 'VarianceScaling',
'config': {
'scale': 2.0,
'mode': 'fan_out',
# EfficientNet actually uses an untruncated normal distribution for
# initializing conv layers, but keras.initializers.VarianceScaling use
# a truncated distribution.
# We decided against a custom initializer for better serializability.
'distribution': 'normal'
}
}
DENSE_KERNEL_INITIALIZER = {
'class_name': 'VarianceScaling',
'config': {
'scale': 1. / 3.,
'mode': 'fan_out',
'distribution': 'uniform'
}
}
def get_swish():
def swish(x):
return x * backend.sigmoid(x)
return swish
def get_dropout():
class FixedDropout(layers.Dropout):
def _get_noise_shape(self, inputs):
if self.noise_shape is None:
return self.noise_shape
symbolic_shape = backend.shape(inputs)
noise_shape = [symbolic_shape[axis] if shape is None else shape
for axis, shape in enumerate(self.noise_shape)]
return tuple(noise_shape)
return FixedDropout
def round_filters(filters, width_coefficient, depth_divisor):
filters *= width_coefficient
new_filters = int(filters + depth_divisor / 2) // depth_divisor * depth_divisor
new_filters = max(depth_divisor, new_filters)
if new_filters < 0.9 * filters:
new_filters += depth_divisor
return int(new_filters)
def round_repeats(repeats, depth_coefficient):
return int(math.ceil(depth_coefficient * repeats))
def mb_conv_block(inputs, block_args, activation, drop_rate=None, prefix='', freeze_bn=False):
has_se = (block_args.se_ratio is not None) and (0 < block_args.se_ratio <= 1)
bn_axis = 3
Dropout = get_dropout()
filters = block_args.input_filters * block_args.expand_ratio
if block_args.expand_ratio != 1:
x = layers.Conv2D(filters, 1,
padding='same',
use_bias=False,
kernel_initializer=CONV_KERNEL_INITIALIZER,
name=prefix + 'expand_conv')(inputs)
x = layers.BatchNormalization(axis=bn_axis, name=prefix + 'expand_bn')(x)
x = layers.Activation(activation, name=prefix + 'expand_activation')(x)
else:
x = inputs
# Depthwise Convolution
x = layers.DepthwiseConv2D(block_args.kernel_size,
strides=block_args.strides,
padding='same',
use_bias=False,
depthwise_initializer=CONV_KERNEL_INITIALIZER,
name=prefix + 'dwconv')(x)
x = layers.BatchNormalization(axis=bn_axis, name=prefix + 'bn')(x)
x = layers.Activation(activation, name=prefix + 'activation')(x)
# Squeeze and Excitation phase
if has_se:
num_reduced_filters = max(1, int(
block_args.input_filters * block_args.se_ratio
))
se_tensor = layers.GlobalAveragePooling2D(name=prefix + 'se_squeeze')(x)
target_shape = (1, 1, filters) if backend.image_data_format() == 'channels_last' else (filters, 1, 1)
se_tensor = layers.Reshape(target_shape, name=prefix + 'se_reshape')(se_tensor)
se_tensor = layers.Conv2D(num_reduced_filters, 1,
activation=activation,
padding='same',
use_bias=True,
kernel_initializer=CONV_KERNEL_INITIALIZER,
name=prefix + 'se_reduce')(se_tensor)
se_tensor = layers.Conv2D(filters, 1,
activation='sigmoid',
padding='same',
use_bias=True,
kernel_initializer=CONV_KERNEL_INITIALIZER,
name=prefix + 'se_expand')(se_tensor)
if backend.backend() == 'theano':
# For the Theano backend, we have to explicitly make
# the excitation weights broadcastable.
pattern = ([True, True, True, False] if backend.image_data_format() == 'channels_last'
else [True, False, True, True])
se_tensor = layers.Lambda(
lambda x: backend.pattern_broadcast(x, pattern),
name=prefix + 'se_broadcast')(se_tensor)
x = layers.multiply([x, se_tensor], name=prefix + 'se_excite')
# Output phase
x = layers.Conv2D(block_args.output_filters, 1,
padding='same',
use_bias=False,
kernel_initializer=CONV_KERNEL_INITIALIZER,
name=prefix + 'project_conv')(x)
# x = BatchNormalization(freeze=freeze_bn, axis=bn_axis, name=prefix + 'project_bn')(x)
x = layers.BatchNormalization(axis=bn_axis, name=prefix + 'project_bn')(x)
if block_args.id_skip and all(
s == 1 for s in block_args.strides
) and block_args.input_filters == block_args.output_filters:
if drop_rate and (drop_rate > 0):
x = Dropout(drop_rate,
noise_shape=(None, 1, 1, 1),
name=prefix + 'drop')(x)
x = layers.add([x, inputs], name=prefix + 'add')
return x
def EfficientNet(width_coefficient,
depth_coefficient,
default_resolution,
dropout_rate=0.2,
drop_connect_rate=0.2,
depth_divisor=8,
blocks_args=DEFAULT_BLOCKS_ARGS,
model_name='efficientnet',
include_top=True,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
freeze_bn=False,
**kwargs):
features = []
if input_tensor is None:
img_input = layers.Input(shape=input_shape)
else:
img_input = input_tensor
bn_axis = 3
activation = get_swish(**kwargs)
# Build stem
x = img_input
x = layers.Conv2D(round_filters(32, width_coefficient, depth_divisor), 3,
strides=(2, 2),
padding='same',
use_bias=False,
kernel_initializer=CONV_KERNEL_INITIALIZER,
name='stem_conv')(x)
# x = BatchNormalization(freeze=freeze_bn, axis=bn_axis, name='stem_bn')(x)
x = layers.BatchNormalization(axis=bn_axis, name='stem_bn')(x)
x = layers.Activation(activation, name='stem_activation')(x)
# Build blocks
num_blocks_total = sum(block_args.num_repeat for block_args in blocks_args)
block_num = 0
for idx, block_args in enumerate(blocks_args):
assert block_args.num_repeat > 0
# Update block input and output filters based on depth multiplier.
block_args = block_args._replace(
input_filters=round_filters(block_args.input_filters,
width_coefficient, depth_divisor),
output_filters=round_filters(block_args.output_filters,
width_coefficient, depth_divisor),
num_repeat=round_repeats(block_args.num_repeat, depth_coefficient))
# The first block needs to take care of stride and filter size increase.
drop_rate = drop_connect_rate * float(block_num) / num_blocks_total
x = mb_conv_block(x, block_args,
activation=activation,
drop_rate=drop_rate,
prefix='block{}a_'.format(idx + 1),
freeze_bn=freeze_bn
)
block_num += 1
if block_args.num_repeat > 1:
# pylint: disable=protected-access
block_args = block_args._replace(
input_filters=block_args.output_filters, strides=[1, 1])
# pylint: enable=protected-access
for bidx in xrange(block_args.num_repeat - 1):
drop_rate = drop_connect_rate * float(block_num) / num_blocks_total
block_prefix = 'block{}{}_'.format(
idx + 1,
string.ascii_lowercase[bidx + 1]
)
x = mb_conv_block(x, block_args,
activation=activation,
drop_rate=drop_rate,
prefix=block_prefix,
freeze_bn=freeze_bn
)
block_num += 1
if idx < len(blocks_args) - 1 and blocks_args[idx + 1].strides[0] == 2:
features.append(x)
elif idx == len(blocks_args) - 1:
features.append(x)
return features
def EfficientNetB0(include_top=True,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
**kwargs):
return EfficientNet(1.0, 1.0, 224, 0.2,
model_name='efficientnet-b0',
include_top=include_top, weights=weights,
input_tensor=input_tensor, input_shape=input_shape,
pooling=pooling, classes=classes,
**kwargs)
def EfficientNetB1(include_top=True,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
**kwargs):
return EfficientNet(1.0, 1.1, 240, 0.2,
model_name='efficientnet-b1',
include_top=include_top, weights=weights,
input_tensor=input_tensor, input_shape=input_shape,
pooling=pooling, classes=classes,
**kwargs)
def EfficientNetB2(include_top=True,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
**kwargs):
return EfficientNet(1.1, 1.2, 260, 0.3,
model_name='efficientnet-b2',
include_top=include_top, weights=weights,
input_tensor=input_tensor, input_shape=input_shape,
pooling=pooling, classes=classes,
**kwargs)
def EfficientNetB3(include_top=True,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
**kwargs):
return EfficientNet(1.2, 1.4, 300, 0.3,
model_name='efficientnet-b3',
include_top=include_top, weights=weights,
input_tensor=input_tensor, input_shape=input_shape,
pooling=pooling, classes=classes,
**kwargs)
def EfficientNetB4(include_top=True,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
**kwargs):
return EfficientNet(1.4, 1.8, 380, 0.4,
model_name='efficientnet-b4',
include_top=include_top, weights=weights,
input_tensor=input_tensor, input_shape=input_shape,
pooling=pooling, classes=classes,
**kwargs)
def EfficientNetB5(include_top=True,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
**kwargs):
return EfficientNet(1.6, 2.2, 456, 0.4,
model_name='efficientnet-b5',
include_top=include_top, weights=weights,
input_tensor=input_tensor, input_shape=input_shape,
pooling=pooling, classes=classes,
**kwargs)
def EfficientNetB6(include_top=True,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
**kwargs):
return EfficientNet(1.8, 2.6, 528, 0.5,
model_name='efficientnet-b6',
include_top=include_top, weights=weights,
input_tensor=input_tensor, input_shape=input_shape,
pooling=pooling, classes=classes,
**kwargs)
def EfficientNetB7(include_top=True,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
**kwargs):
return EfficientNet(2.0, 3.1, 600, 0.5,
model_name='efficientnet-b7',
include_top=include_top, weights=weights,
input_tensor=input_tensor, input_shape=input_shape,
pooling=pooling, classes=classes,
**kwargs)
2、BiFPN加强特征提取
BiFPN简单来讲是一个加强版本的FPN,上图是BiFPN,下图是普通的FPN,大家可以看到,与普通的FPN相比,BiFPN的FPN构建更加复杂,中间还增加了许多连接。

构建BiFPN可以分为多步:
1、获得P3_in、P4_in、P5_in、P6_in、P7_in,通过主干特征提取网络,我们已经可以获得P3、P4、P5,还需要进行两次下采样获得P6、P7。
P3、P4、P5在经过1x1卷积调整通道数后,就可以作为P3_in、P4_in、P5_in了,在构建BiFPN的第一步,需要构建两个P4_in、P5_in(原版是这样设计的)。

实现代码如下:
_, _, C3, C4, C5 = features
# 第一次BIFPN需要 下采样 与 降通道 获得 p3_in p4_in p5_in p6_in p7_in
#-----------------------------下采样 与 降通道----------------------------#
P3_in = C3
P3_in = layers.Conv2D(num_channels, kernel_size=1, padding='same',
name=f'fpn_cells/cell_{id}/fnode3/resample_0_0_8/conv2d')(P3_in)
P3_in = layers.BatchNormalization(momentum=MOMENTUM, epsilon=EPSILON,
name=f'fpn_cells/cell_{id}/fnode3/resample_0_0_8/bn')(P3_in)
P4_in = C4
P4_in_1 = layers.Conv2D(num_channels, kernel_size=1, padding='same',
name=f'fpn_cells/cell_{id}/fnode2/resample_0_1_7/conv2d')(P4_in)
P4_in_1 = layers.BatchNormalization(momentum=MOMENTUM, epsilon=EPSILON,
name=f'fpn_cells/cell_{id}/fnode2/resample_0_1_7/bn')(P4_in_1)
P4_in_2 = layers.Conv2D(num_channels, kernel_size=1, padding='same',
name=f'fpn_cells/cell_{id}/fnode4/resample_0_1_9/conv2d')(P4_in)
P4_in_2 = layers.BatchNormalization(momentum=MOMENTUM, epsilon=EPSILON,
name=f'fpn_cells/cell_{id}/fnode4/resample_0_1_9/bn')(P4_in_2)
P5_in = C5
P5_in_1 = layers.Conv2D(num_channels, kernel_size=1, padding='same',
name=f'fpn_cells/cell_{id}/fnode1/resample_0_2_6/conv2d')(P5_in)
P5_in_1 = layers.BatchNormalization(momentum=MOMENTUM, epsilon=EPSILON,
name=f'fpn_cells/cell_{id}/fnode1/resample_0_2_6/bn')(P5_in_1)
P5_in_2 = layers.Conv2D(num_channels, kernel_size=1, padding='same',
name=f'fpn_cells/cell_{id}/fnode5/resample_0_2_10/conv2d')(P5_in)
P5_in_2 = layers.BatchNormalization(momentum=MOMENTUM, epsilon=EPSILON,
name=f'fpn_cells/cell_{id}/fnode5/resample_0_2_10/bn')(P5_in_2)
P6_in = layers.Conv2D(num_channels, kernel_size=1, padding='same', name='resample_p6/conv2d')(C5)
P6_in = layers.BatchNormalization(momentum=MOMENTUM, epsilon=EPSILON, name='resample_p6/bn')(P6_in)
P6_in = layers.MaxPooling2D(pool_size=3, strides=2, padding='same', name='resample_p6/maxpool')(P6_in)
P7_in = layers.MaxPooling2D(pool_size=3, strides=2, padding='same', name='resample_p7/maxpool')(P6_in)
#-------------------------------------------------------------------------#
2、在获得P3_in、P4_in_1、P4_in_2、P5_in_1、P5_in_2、P6_in、P7_in之后需要对P7_in进行上采样,上采样后与P6_in堆叠获得P6_td;之后对P6_td进行上采样,上采样后与P5_in_1进行堆叠获得P5_td;之后对P5_td进行上采样,上采样后与P4_in_1进行堆叠获得P4_td;之后对P4_td进行上采样,上采样后与P3_in进行堆叠获得P3_out。

实现代码如下:
#--------------------------构建BIFPN的上下采样循环-------------------------#
P7_U = layers.UpSampling2D()(P7_in)
P6_td = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode0/add')([P6_in, P7_U])
P6_td = layers.Activation(lambda x: tf.nn.swish(x))(P6_td)
P6_td = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,
name=f'fpn_cells/cell_{id}/fnode0/op_after_combine5')(P6_td)
P6_U = layers.UpSampling2D()(P6_td)
P5_td = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode1/add')([P5_in_1, P6_U])
P5_td = layers.Activation(lambda x: tf.nn.swish(x))(P5_td)
P5_td = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,
name=f'fpn_cells/cell_{id}/fnode1/op_after_combine6')(P5_td)
P5_U = layers.UpSampling2D()(P5_td)
P4_td = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode2/add')([P4_in_1, P5_U])
P4_td = layers.Activation(lambda x: tf.nn.swish(x))(P4_td)
P4_td = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,
name=f'fpn_cells/cell_{id}/fnode2/op_after_combine7')(P4_td)
P4_U = layers.UpSampling2D()(P4_td)
P3_out = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode3/add')([P3_in, P4_U])
P3_out = layers.Activation(lambda x: tf.nn.swish(x))(P3_out)
P3_out = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,
name=f'fpn_cells/cell_{id}/fnode3/op_after_combine8')(P3_out)
#-------------------------------------------------------------------------#
3、在获得P3_out、P4_td、P4_in_2、P5_td、P5_in_2、P6_in、P6_td、P7_in之后,之后需要对P3_out进行下采样,下采样后与P4_td、P4_in_2堆叠获得P4_out;之后对P4_out进行下采样,下采样后与P5_td、P5_in_2进行堆叠获得P5_out;之后对P5_out进行下采样,下采样后与P6_in、P6_td进行堆叠获得P6_out;之后对P6_out进行下采样,下采样后与P7_in进行堆叠获得P7_out。

实现代码如下:
#--------------------------构建BIFPN的上下采样循环-------------------------#
P3_D = layers.MaxPooling2D(pool_size=3, strides=2, padding='same')(P3_out)
P4_out = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode4/add')([P4_in_2, P4_td, P3_D])
P4_out = layers.Activation(lambda x: tf.nn.swish(x))(P4_out)
P4_out = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,
name=f'fpn_cells/cell_{id}/fnode4/op_after_combine9')(P4_out)
P4_D = layers.MaxPooling2D(pool_size=3, strides=2, padding='same')(P4_out)
P5_out = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode5/add')([P5_in_2, P5_td, P4_D])
P5_out = layers.Activation(lambda x: tf.nn.swish(x))(P5_out)
P5_out = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,
name=f'fpn_cells/cell_{id}/fnode5/op_after_combine10')(P5_out)
P5_D = layers.MaxPooling2D(pool_size=3, strides=2, padding='same')(P5_out)
P6_out = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode6/add')([P6_in, P6_td, P5_D])
P6_out = layers.Activation(lambda x: tf.nn.swish(x))(P6_out)
P6_out = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,
name=f'fpn_cells/cell_{id}/fnode6/op_after_combine11')(P6_out)
P6_D = layers.MaxPooling2D(pool_size=3, strides=2, padding='same')(P6_out)
P7_out = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode7/add')([P7_in, P6_D])
P7_out = layers.Activation(lambda x: tf.nn.swish(x))(P7_out)
P7_out = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,
name=f'fpn_cells/cell_{id}/fnode7/op_after_combine12')(P7_out)
#-------------------------------------------------------------------------#
4、将获得的P3_out、P4_out、P5_out、P6_out、P7_out作为P3_in、P4_in、P5_in、P6_in、P7_in,重复2、3步骤进行堆叠即可,对于Effiicientdet B0来讲,还需要重复2次,需要注意P4_in_1和P4_in_2此时不需要分开了,P5也是。

实现代码如下:
P3_in, P4_in, P5_in, P6_in, P7_in = features
P7_U = layers.UpSampling2D()(P7_in)
P6_td = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode0/add')([P6_in, P7_U])
P6_td = layers.Activation(lambda x: tf.nn.swish(x))(P6_td)
P6_td = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,
name=f'fpn_cells/cell_{id}/fnode0/op_after_combine5')(P6_td)
P6_U = layers.UpSampling2D()(P6_td)
P5_td = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode1/add')([P5_in, P6_U])
P5_td = layers.Activation(lambda x: tf.nn.swish(x))(P5_td)
P5_td = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,
name=f'fpn_cells/cell_{id}/fnode1/op_after_combine6')(P5_td)
P5_U = layers.UpSampling2D()(P5_td)
P4_td = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode2/add')([P4_in, P5_U])
P4_td = layers.Activation(lambda x: tf.nn.swish(x))(P4_td)
P4_td = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,
name=f'fpn_cells/cell_{id}/fnode2/op_after_combine7')(P4_td)
P4_U = layers.UpSampling2D()(P4_td)
P3_out = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode3/add')([P3_in, P4_U])
P3_out = layers.Activation(lambda x: tf.nn.swish(x))(P3_out)
P3_out = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,
name=f'fpn_cells/cell_{id}/fnode3/op_after_combine8')(P3_out)
P3_D = layers.MaxPooling2D(pool_size=3, strides=2, padding='same')(P3_out)
P4_out = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode4/add')([P4_in, P4_td, P3_D])
P4_out = layers.Activation(lambda x: tf.nn.swish(x))(P4_out)
P4_out = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,
name=f'fpn_cells/cell_{id}/fnode4/op_after_combine9')(P4_out)
P4_D = layers.MaxPooling2D(pool_size=3, strides=2, padding='same')(P4_out)
P5_out = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode5/add')([P5_in, P5_td, P4_D])
P5_out = layers.Activation(lambda x: tf.nn.swish(x))(P5_out)
P5_out = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,
name=f'fpn_cells/cell_{id}/fnode5/op_after_combine10')(P5_out)
P5_D = layers.MaxPooling2D(pool_size=3, strides=2, padding='same')(P5_out)
P6_out = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode6/add')([P6_in, P6_td, P5_D])
P6_out = layers.Activation(lambda x: tf.nn.swish(x))(P6_out)
P6_out = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,
name=f'fpn_cells/cell_{id}/fnode6/op_after_combine11')(P6_out)
P6_D = layers.MaxPooling2D(pool_size=3, strides=2, padding='same')(P6_out)
P7_out = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode7/add')([P7_in, P6_D])
P7_out = layers.Activation(lambda x: tf.nn.swish(x))(P7_out)
P7_out = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,
name=f'fpn_cells/cell_{id}/fnode7/op_after_combine12')(P7_out)
3、从特征获取预测结果
通过第二部的重复运算,我们获得了P3_out, P4_out, P5_out, P6_out, P7_out。
为了和普通特征层区分,我们称之为有效特征层,将这五个有效的特征层传输过ClassNet+BoxNet就可以获得预测结果了。
对于Efficientdet-B0来讲:
ClassNet采用3次64通道的卷积和1次num_priors x num_classes的卷积,num_priors指的是该特征层所拥有的先验框数量,num_classes指的是网络一共对多少类的目标进行检测。
BoxNet采用3次64通道的卷积和1次num_priors x 4的卷积,num_priors指的是该特征层所拥有的先验框数量,4指的是先验框的调整情况。
需要注意的是,每个特征层所用的ClassNet是同一个ClassNet;每个特征层所用的BoxNet是同一个BoxNet。
其中:
num_priors x 4的卷积 用于预测 该特征层上 每一个网格点上 每一个先验框的变化情况。**
num_priors x num_classes的卷积 用于预测 该特征层上 每一个网格点上 每一个预测框对应的种类。
实现代码为:
class BoxNet:
def __init__(self, width, depth, num_anchors=9, freeze_bn=False, name='box_net', **kwargs):
self.name = name
self.width = width
self.depth = depth
self.num_anchors = num_anchors
options = {
'kernel_size': 3,
'strides': 1,
'padding': 'same',
'bias_initializer': 'zeros',
'depthwise_initializer': initializers.VarianceScaling(),
'pointwise_initializer': initializers.VarianceScaling(),
}
self.convs = [layers.SeparableConv2D(filters=width, name=f'{self.name}/box-{i}', **options) for i in range(depth)]
self.head = layers.SeparableConv2D(filters=num_anchors * 4, name=f'{self.name}/box-predict', **options)
self.bns = [
[layers.BatchNormalization(momentum=MOMENTUM, epsilon=EPSILON, name=f'{self.name}/box-{i}-bn-{j}') for j in
range(3, 8)]
for i in range(depth)]
self.relu = layers.Lambda(lambda x: tf.nn.swish(x))
self.reshape = layers.Reshape((-1, 4))
def call(self, inputs):
feature, level = inputs
for i in range(self.depth):
feature = self.convs[i](feature)
feature = self.bns[i][level](feature)
feature = self.relu(feature)
outputs = self.head(feature)
outputs = self.reshape(outputs)
return outputs
class ClassNet:
def __init__(self, width, depth, num_classes=20, num_anchors=9, freeze_bn=False, name='class_net', **kwargs):
self.name = name
self.width = width
self.depth = depth
self.num_classes = num_classes
self.num_anchors = num_anchors
options = {
'kernel_size': 3,
'strides': 1,
'padding': 'same',
'depthwise_initializer': initializers.VarianceScaling(),
'pointwise_initializer': initializers.VarianceScaling(),
}
self.convs = [layers.SeparableConv2D(filters=width, bias_initializer='zeros', name=f'{self.name}/class-{i}',
**options)
for i in range(depth)]
self.head = layers.SeparableConv2D(filters=num_classes * num_anchors,
bias_initializer=PriorProbability(probability=0.01),
name=f'{self.name}/class-predict', **options)
self.bns = [
[layers.BatchNormalization(momentum=MOMENTUM, epsilon=EPSILON, name=f'{self.name}/class-{i}-bn-{j}') for j
in range(3, 8)]
for i in range(depth)]
self.relu = layers.Lambda(lambda x: tf.nn.swish(x))
self.reshape = layers.Reshape((-1, num_classes))
self.activation = layers.Activation('sigmoid')
def call(self, inputs):
feature, level = inputs
for i in range(self.depth):
feature = self.convs[i](feature)
feature = self.bns[i][level](feature)
feature = self.relu(feature)
outputs = self.head(feature)
outputs = self.reshape(outputs)
outputs = self.activation(outputs)
return outputs
4、预测结果的解码
我们通过对每一个特征层的处理,可以获得三个内容,分别是:
num_priors x 4的卷积 用于预测 该特征层上 每一个网格点上 每一个先验框的变化情况。**
num_priors x num_classes的卷积 用于预测 该特征层上 每一个网格点上 每一个预测框对应的种类。
每一个有效特征层对应的先验框对应着该特征层上 每一个网格点上 预先设定好的9个框。
我们利用 num_priors x 4的卷积 与 每一个有效特征层对应的先验框 获得框的真实位置。
每一个有效特征层对应的先验框就是,如图所示的作用:
每一个有效特征层将整个图片分成与其长宽对应的网格,如P3的特征层就是将整个图像分成64x64个网格;然后从每个网格中心建立9个先验框,一共64x64x9个,36864个先验框。

先验框虽然可以代表一定的框的位置信息与框的大小信息,但是其是有限的,无法表示任意情况,因此还需要调整,Efficientdet利用3次64通道的卷积+num_priors x 4的卷积的结果对先验框进行调整。
num_priors x 4中的num_priors表示了这个网格点所包含的先验框数量,其中的4表示了框的左上角xy轴,右下角xy的调整情况。
Efficientdet解码过程就是将对应的先验框的左上角和右下角进行位置的调整,调整完的结果就是预测框的位置了。
当然得到最终的预测结构后还要进行得分排序与非极大抑制筛选这一部分基本上是所有目标检测通用的部分。
1、取出每一类得分大于confidence_threshold的框和得分。
2、利用框的位置和得分进行非极大抑制。
实现代码如下:
def decode_boxes(self, mbox_loc, mbox_priorbox):
# 获得先验框的宽与高
prior_width = mbox_priorbox[:, 2] - mbox_priorbox[:, 0]
prior_height = mbox_priorbox[:, 3] - mbox_priorbox[:, 1]
# 获得先验框的中心点
prior_center_x = 0.5 * (mbox_priorbox[:, 2] + mbox_priorbox[:, 0])
prior_center_y = 0.5 * (mbox_priorbox[:, 3] + mbox_priorbox[:, 1])
# 真实框距离先验框中心的xy轴偏移情况
decode_bbox_center_x = mbox_loc[:, 0] * prior_width * 0.1
decode_bbox_center_x += prior_center_x
decode_bbox_center_y = mbox_loc[:, 1] * prior_height * 0.1
decode_bbox_center_y += prior_center_y
# 真实框的宽与高的求取
decode_bbox_width = np.exp(mbox_loc[:, 2] * 0.2)
decode_bbox_width *= prior_width
decode_bbox_height = np.exp(mbox_loc[:, 3] * 0.2)
decode_bbox_height *= prior_height
# 获取真实框的左上角与右下角
decode_bbox_xmin = decode_bbox_center_x - 0.5 * decode_bbox_width
decode_bbox_ymin = decode_bbox_center_y - 0.5 * decode_bbox_height
decode_bbox_xmax = decode_bbox_center_x + 0.5 * decode_bbox_width
decode_bbox_ymax = decode_bbox_center_y + 0.5 * decode_bbox_height
# 真实框的左上角与右下角进行堆叠
decode_bbox = np.concatenate((decode_bbox_xmin[:, None],
decode_bbox_ymin[:, None],
decode_bbox_xmax[:, None],
decode_bbox_ymax[:, None]), axis=-1)
# 防止超出0与1
decode_bbox = np.minimum(np.maximum(decode_bbox, 0.0), 1.0)
return decode_bbox
def detection_out(self, predictions, mbox_priorbox, background_label_id=0, keep_top_k=200,
confidence_threshold=0.4):
# 网络预测的结果
mbox_loc = predictions[0]
# 先验框
mbox_priorbox = mbox_priorbox
# 置信度
mbox_conf = predictions[1]
results = []
# 对每一个图片进行处理
for i in range(len(mbox_loc)):
results.append([])
decode_bbox = self.decode_boxes(mbox_loc[i], mbox_priorbox)
for c in range(self.num_classes):
c_confs = mbox_conf[i, :, c]
c_confs_m = c_confs > confidence_threshold
if len(c_confs[c_confs_m]) > 0:
# 取出得分高于confidence_threshold的框
boxes_to_process = decode_bbox[c_confs_m]
confs_to_process = c_confs[c_confs_m]
# 进行iou的非极大抑制
feed_dict = {self.boxes: boxes_to_process,
self.scores: confs_to_process}
idx = self.sess.run(self.nms, feed_dict=feed_dict)
# 取出在非极大抑制中效果较好的内容
good_boxes = boxes_to_process[idx]
confs = confs_to_process[idx][:, None]
# 将label、置信度、框的位置进行堆叠。
labels = c * np.ones((len(idx), 1))
c_pred = np.concatenate((labels, confs, good_boxes),
axis=1)
# 添加进result里
results[-1].extend(c_pred)
if len(results[-1]) > 0:
# 按照置信度进行排序
results[-1] = np.array(results[-1])
argsort = np.argsort(results[-1][:, 1])[::-1]
results[-1] = results[-1][argsort]
# 选出置信度最大的keep_top_k个
results[-1] = results[-1][:keep_top_k]
# 获得,在所有预测结果里面,置信度比较高的框
# 还有,利用先验框和m2det的预测结果,处理获得了真实框(预测框)的位置
return results
5、在原图上进行绘制
通过第三步,我们可以获得预测框在原图上的位置,而且这些预测框都是经过筛选的。这些筛选后的框可以直接绘制在图片上,就可以获得结果了。
二、训练部分
1、真实框的处理
从预测部分我们知道,每个特征层的预测结果,num_priors x 4的卷积 用于预测 该特征层上 每一个网格点上 每一个先验框的变化情况。
也就是说,我们直接利用Efficientdet网络预测到的结果,并不是预测框在图片上的真实位置,需要解码才能得到真实位置。
而在训练的时候,我们需要计算loss函数,这个loss函数是相对于Efficientdet网络的预测结果的。我们需要把图片输入到当前的Efficientdet网络中,得到预测结果;同时还需要把真实框的信息,进行编码,这个编码是把真实框的位置信息格式转化为Efficientdet预测结果的格式信息。
也就是,我们需要找到 每一张用于训练的图片的每一个真实框对应的先验框,并求出如果想要得到这样一个真实框,我们的预测结果应该是怎么样的。
从预测结果获得真实框的过程被称作解码,而从真实框获得预测结果的过程就是编码的过程。
因此我们只需要将解码过程逆过来就是编码过程了。
实现代码如下:
def encode_box(self, box, return_iou=True):
iou = self.iou(box)
encoded_box = np.zeros((self.num_priors, 4 + return_iou))
# 找到每一个真实框,重合程度较高的先验框
assign_mask = iou > self.overlap_threshold
if not assign_mask.any():
assign_mask[iou.argmax()] = True
if return_iou:
encoded_box[:, -1][assign_mask] = iou[assign_mask]
# 找到对应的先验框
assigned_priors = self.priors[assign_mask]
# 逆向编码,将真实框转化为Efficientdet预测结果的格式
assigned_priors_w = (assigned_priors[:, 2] -
assigned_priors[:, 0])
assigned_priors_h = (assigned_priors[:, 3] -
assigned_priors[:, 1])
encoded_box[:,0][assign_mask] = (box[0] - assigned_priors[:, 0])/assigned_priors_w/0.2
encoded_box[:,1][assign_mask] = (box[1] - assigned_priors[:, 1])/assigned_priors_h/0.2
encoded_box[:,2][assign_mask] = (box[2] - assigned_priors[:, 2])/assigned_priors_w/0.2
encoded_box[:,3][assign_mask] = (box[3] - assigned_priors[:, 3])/assigned_priors_h/0.2
return encoded_box.ravel()
利用上述代码我们可以获得,真实框对应的所有的iou较大先验框,并计算了真实框对应的所有iou较大的先验框应该有的预测结果。
但是由于原始图片中可能存在多个真实框,可能同一个先验框会与多个真实框重合度较高,我们只取其中与真实框重合度最高的就可以了。
因此我们还要经过一次筛选,将上述代码获得的真实框对应的所有的iou较大先验框的预测结果中,iou最大的那个真实框筛选出来。
通过assign_boxes我们就获得了,输入进来的这张图片,应该有的预测结果是什么样子的。
实现代码如下:
def assign_boxes(self, boxes):
assignment = np.zeros((self.num_priors, 4 + 1 + self.num_classes + 1))
assignment[:, 4] = 0.0
assignment[:, -1] = 0.0
if len(boxes) == 0:
return assignment
# 对每一个真实框都进行iou计算
ingored_boxes = np.apply_along_axis(self.ignore_box, 1, boxes[:, :4])
# 取重合程度最大的先验框,并且获取这个先验框的index
ingored_boxes = ingored_boxes.reshape(-1, self.num_priors, 1)
# (num_priors)
ignore_iou = ingored_boxes[:, :, 0].max(axis=0)
# (num_priors)
ignore_iou_mask = ignore_iou > 0
assignment[:, 4][ignore_iou_mask] = -1
assignment[:, -1][ignore_iou_mask] = -1
# (n, num_priors, 5)
encoded_boxes = np.apply_along_axis(self.encode_box, 1, boxes[:, :4])
# 每一个真实框的编码后的值,和iou
# (n, num_priors)
encoded_boxes = encoded_boxes.reshape(-1, self.num_priors, 5)
# 取重合程度最大的先验框,并且获取这个先验框的index
# (num_priors)
best_iou = encoded_boxes[:, :, -1].max(axis=0)
# (num_priors)
best_iou_idx = encoded_boxes[:, :, -1].argmax(axis=0)
# (num_priors)
best_iou_mask = best_iou > 0
# 某个先验框它属于哪个真实框
best_iou_idx = best_iou_idx[best_iou_mask]
assign_num = len(best_iou_idx)
# 保留重合程度最大的先验框的应该有的预测结果
# 哪些先验框存在真实框
encoded_boxes = encoded_boxes[:, best_iou_mask, :]
assignment[:, :4][best_iou_mask] = encoded_boxes[best_iou_idx,np.arange(assign_num),:4]
# 4代表为背景的概率,为0
assignment[:, 4][best_iou_mask] = 1
assignment[:, 5:-1][best_iou_mask] = boxes[best_iou_idx, 4:]
assignment[:, -1][best_iou_mask] = 1
# 通过assign_boxes我们就获得了,输入进来的这张图片,应该有的预测结果是什么样子的
return assignment
focal会忽略一些重合度相对较高但是不是非常高的先验框,一般将重合度在0.4-0.5之间的先验框进行忽略。
实现代码如下:
def ignore_box(self, box):
iou = self.iou(box)
ignored_box = np.zeros((self.num_priors, 1))
# 找到每一个真实框,重合程度较高的先验框
assign_mask = (iou > self.ignore_threshold)&(iou<self.overlap_threshold)
if not assign_mask.any():
assign_mask[iou.argmax()] = True
ignored_box[:, 0][assign_mask] = iou[assign_mask]
return ignored_box.ravel()
2、利用处理完的真实框与对应图片的预测结果计算loss
loss的计算分为两个部分:
1、Smooth Loss:获取所有正标签的框的预测结果的回归loss。
2、Focal Loss:获取所有未被忽略的种类的预测结果的交叉熵loss。
由于在Efficientdet的训练过程中,正负样本极其不平衡,即 存在对应真实框的先验框可能只有若干个,但是不存在对应真实框的负样本却有上万个,这就会导致负样本的loss值极大,因此引入了Focal Loss进行正负样本的平衡,关于Focal Loss的介绍可以看这个博客。
https://blog.csdn.net/weixin_44791964/article/details/102853782
实现代码如下:
def focal(alpha=0.25, gamma=2.0):
def _focal(y_true, y_pred):
# y_true [batch_size, num_anchor, num_classes+1]
# y_pred [batch_size, num_anchor, num_classes]
labels = y_true[:, :, :-1]
anchor_state = y_true[:, :, -1] # -1 是需要忽略的, 0 是背景, 1 是存在目标
classification = y_pred
# 找出存在目标的先验框
indices_for_object = backend.where(keras.backend.equal(anchor_state, 1))
labels_for_object = backend.gather_nd(labels, indices_for_object)
classification_for_object = backend.gather_nd(classification, indices_for_object)
# 计算每一个先验框应该有的权重
alpha_factor_for_object = keras.backend.ones_like(labels_for_object) * alpha
alpha_factor_for_object = backend.where(keras.backend.equal(labels_for_object, 1), alpha_factor_for_object, 1 - alpha_factor_for_object)
focal_weight_for_object = backend.where(keras.backend.equal(labels_for_object, 1), 1 - classification_for_object, classification_for_object)
focal_weight_for_object = alpha_factor_for_object * focal_weight_for_object ** gamma
# 将权重乘上所求得的交叉熵
cls_loss_for_object = focal_weight_for_object * keras.backend.binary_crossentropy(labels_for_object, classification_for_object)
# 找出实际上为背景的先验框
indices_for_back = backend.where(keras.backend.equal(anchor_state, 0))
labels_for_back = backend.gather_nd(labels, indices_for_back)
classification_for_back = backend.gather_nd(classification, indices_for_back)
# 计算每一个先验框应该有的权重
alpha_factor_for_back = keras.backend.ones_like(labels_for_back) * alpha
alpha_factor_for_back = backend.where(keras.backend.equal(labels_for_back, 1), alpha_factor_for_back, 1 - alpha_factor_for_back)
focal_weight_for_back = backend.where(keras.backend.equal(labels_for_back, 1), 1 - classification_for_back, classification_for_back)
focal_weight_for_back = alpha_factor_for_back * focal_weight_for_back ** gamma
# 将权重乘上所求得的交叉熵
cls_loss_for_back = focal_weight_for_back * keras.backend.binary_crossentropy(labels_for_back, classification_for_back)
# 标准化,实际上是正样本的数量
normalizer = tf.where(keras.backend.equal(anchor_state, 1))
normalizer = keras.backend.cast(keras.backend.shape(normalizer)[0], keras.backend.floatx())
normalizer = keras.backend.maximum(keras.backend.cast_to_floatx(1.0), normalizer)
# 将所获得的loss除上正样本的数量
cls_loss_for_object = keras.backend.sum(cls_loss_for_object)
cls_loss_for_back = keras.backend.sum(cls_loss_for_back)
# 总的loss
loss = (cls_loss_for_object + cls_loss_for_back)/normalizer
return loss
return _focal
def smooth_l1(sigma=3.0):
sigma_squared = sigma ** 2
def _smooth_l1(y_true, y_pred):
# y_true [batch_size, num_anchor, 4+1]
# y_pred [batch_size, num_anchor, 4]
regression = y_pred
regression_target = y_true[:, :, :-1]
anchor_state = y_true[:, :, -1]
# 找到正样本
indices = tf.where(keras.backend.equal(anchor_state, 1))
regression = tf.gather_nd(regression, indices)
regression_target = tf.gather_nd(regression_target, indices)
# 计算 smooth L1 loss
# f(x) = 0.5 * (sigma * x)^2 if |x| < 1 / sigma / sigma
# |x| - 0.5 / sigma / sigma otherwise
regression_diff = regression - regression_target
regression_diff = keras.backend.abs(regression_diff)
regression_loss = backend.where(
keras.backend.less(regression_diff, 1.0 / sigma_squared),
0.5 * sigma_squared * keras.backend.pow(regression_diff, 2),
regression_diff - 0.5 / sigma_squared
)
normalizer = keras.backend.maximum(1, keras.backend.shape(indices)[0])
normalizer = keras.backend.cast(normalizer, dtype=keras.backend.floatx())
loss = keras.backend.sum(regression_loss) / normalizer
return loss
return _smooth_l1
训练自己的Efficientdet模型
Efficientdet整体的文件夹构架如下:

本文使用VOC格式进行训练。
训练前将标签文件放在VOCdevkit文件夹下的VOC2007文件夹下的Annotation中。
训练前将图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中。

在训练前利用voc2efficientdet.py文件生成对应的txt。

再运行根目录下的voc_annotation.py,运行前需要将classes改成你自己的classes。
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]

就会生成对应的2007_train.txt,每一行对应其图片位置及其真实框的位置。

在训练前需要修改model_data里面的voc_classes.txt文件,需要将classes改成你自己的classes。

运行train.py即可开始训练。

修改train.py文件下的phi可以修改efficientdet的版本,训练前注意权重文件与Efficientdet版本的对齐。
以上就是Keras搭建Efficientdet目标检测平台的详细内容,更多关于Efficientdet目标检测的资料请关注其它相关文章!


