如何使用正则匹配最后一个字符串详解
前几天遇到一个需求,输入的是
<user>
<user>
<name>a</name>
</user>
<user>
<name>a</name>
</user>
</user>
<password>123</password>
要求拿到
<user>
<user>
<name>a</name>
</user>
<user>
<name>a</name>
</user>
</user>
也就是去掉最后一个</user>后面的字符串。
方法有很多,我首先想到的是用正则匹配去掉</user>后面的字符串。
最后写出来的表达式是
(?<=</user>)(?![\w\W]*</user>)[\w\W]+。
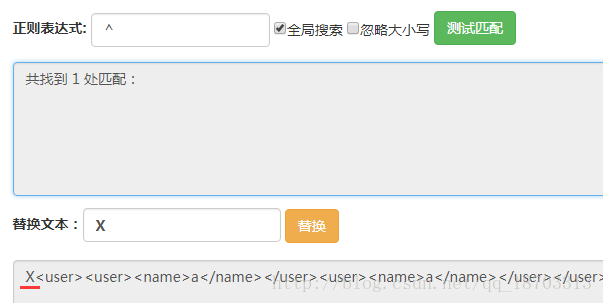
首先用(?<=</user>)匹配所有前面是</user>的位置,如图,总共有三个位置。

这里我们正则表达式(?<=</user>)的意思就是匹配的位置之前的字符串是</user>,也就是我们匹配到的位置在</user>之后。
这里用到了正则表达式语法中的断言,有的书上也称该语法为预查或者环视,都是一样的用法。有如下语法:
(?=pattern) 零宽正向先行断言 (?!pattern) 零宽负向先行断言 (?<=pattern) 零宽正向后行断言 (?<!pattern) 零宽负向后行断言
这里用到的是(?<=pattern),零宽表示它匹配的是在字符串中的位置,如同^匹配字符串串首,$匹配字符串串尾。正向代表它必须满足pattern。后行代表它匹配的位置在pattern之后。
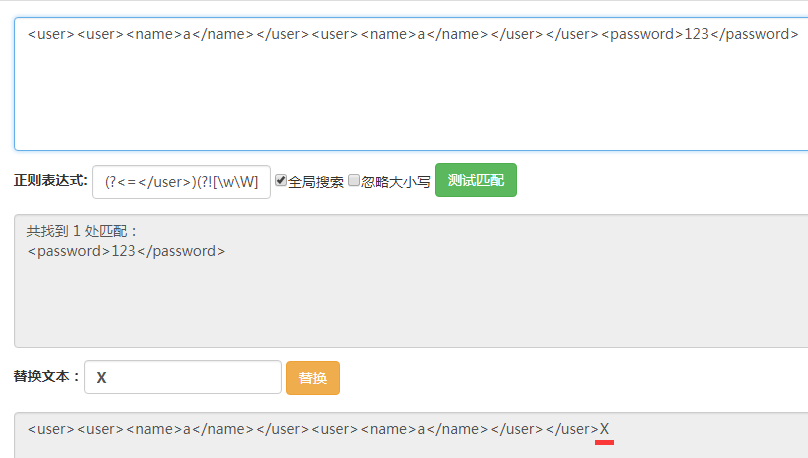
其次,再这三个位置上进行筛选,能够看出这三个位置的区别是后面是否有</user>,如果没有的话那么它就是最后一个</user>后面的位置。在之前的表达式后面添上(?![\w\W]*?</user>)此时表达式变为(?<=</user>)(?![\w\W]*?</user>)。

能够看到得到了最后一个匹配结果。
这里的正则表达式(?!pattern) 是零宽负向先行断言,也就是它会往后匹配pattern,匹配到的位置在pattern之前,并且匹配到的字符串必须不满足pattern。
(?![\w\W]*?</user>)的意思是在匹配到的位置后面必须不是[\w\W]*?</user>,\w匹配的是[a-zA-Z0-9_]即匹配字母数字和下划线,而\W匹配的是[^a-zA-Z0-9_]即不是字母数字也不是下划线的字符,同时匹配这两个就相当于匹配任意字符。[\w\W]后面的*代表匹配0-任意多次,后面的?代表懒惰模式,即只要满足条件就立即返回。
最后,在之前的正则表达式后面加上[\w\W]+贪婪匹配即尽可能多的匹配该位置后面的字符串。最终的正则表达式是(?<=</user>)(?![\w\W]*?</user>)[\w\W]*
最后的最后用四张图简单地描述四种断言的不同之处。
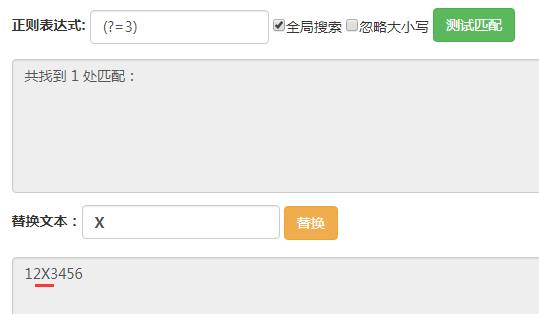
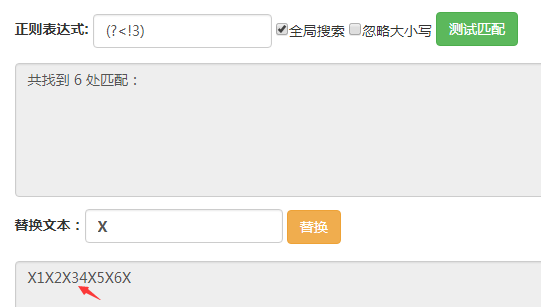
这里输入的字符串都是123456。
(?=3),它匹配的位置是后面的字符为3的位置。
(?<=3),它匹配的位置是前面的字符为3的位置。

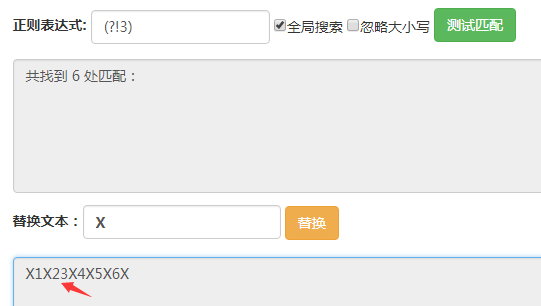
(?!3)匹配的位置是后面的字符不为3的位置,可以看到箭头所指的地方没有被匹配到,其他位置都被匹配到了。
(?<!3)匹配的位置是前面的字符不为3的位置,可以看到箭头所指的地方没有被匹配到,其他位置都被匹配到了。
总结
到此这篇关于如何使用正则匹配最后一个字符串详解的文章就介绍到这了,更多相关正则匹配最后一个字符串内容请搜索 以前的文章或继续浏览下面的相关文章希望大家以后多多支持 !


