Puppet使用方法总结
puppet是一个开源的软件自动化配置和部署工具,它使用简单且功能强大,正得到了越来越多地关注,现在很多大型IT公司均在使用puppet对集群中的软件进行管理和部署,如google利用puppet管理超过6000台地mac桌面电脑(2007年数据)。
本文主要介绍puppet安装方法,设计架构及使用方法。
2. 设计架构
puppet是基于c/s架构的。服务器端保存着所有对客户端服务器的配置代码,在puppet里面叫做manifest. 客户端下载manifest之后,可以根据manifest对服务器进行配置,例如软件包管理,用户管理和文件管理等等。
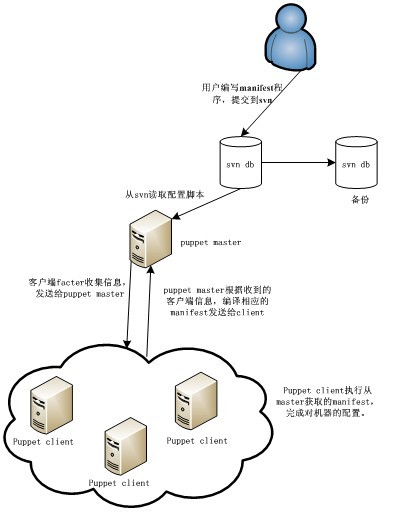
如上图所示,puppet的工作流程如下:(1)客户端puppetd调用facter,facter探测出主机的一些变量,例如主机名,内存大小,ip地址等。pupppetd 把这些信息通过ssl连接发送到服务器端; (2)服务器端的puppetmaster 检测客户端的主机名,然后找到manifest里面对应的node配置, 并对该部分内容进行解析,facter送过来的信息可以作为变量处理,node牵涉到的代码才解析,其他没牵涉的代码不解析。解析分为几个阶段,语法检查,如果语法错误就报错。如果语法没错,就继续解析,解析的结果生成一个中间的“伪代码”,然后把伪代码发给客户端;(3)客户端接收到“伪代码”,并且执行,客户端把执行结果发送给服务器;(4)服务器端把客户端的执行结果写入日志。
puppet工作过程中有两点值得注意,第一,为了保证安全,client和master之间是基于ssl和证书的,只有经master证书认证的client可以与master通信;第二,puppet会让系统保持在你所期望的某种状态并一直维持下去,如检测某个文件并保证其一直存在,保证ssh服务始终开启,如果文件被删除了或者ssh服务被关闭了,puppet下次执行时(默认30分钟),会重新创建该文件或者启动ssh服务。
3. 软件安装
不推荐使用apt-get命令进行安装,因为该命令下载的puppet存在bug。可直接从源代码进行安装,需要安装的软件有ruby,facter和puppet。
3.1 安装步骤
编辑/etc/host以修改主机名,因为puppet是基于证书的,证书中包含主机名;
在master和slave上依次安装ruby、facter和puppet,安装facter和puppet时,要使用ruby install.rb。
3.2 安装后的目录结构
(1) 安装目录
安装目录默认存为/etc/puppet,该目录下的manifests存放manifest文件。
其他可执行文件在/user/sbin下,主要有:
puppet: 用于执行用户所写独立的mainfests文件,如:
puppet -l /tmp/manifest.log manifest.pp
puppetd: 运行在被管理主机上的客户端程序,如:
puppet –server servername –waitforcert 60
puppetmasterd:运行在管理机上的服务器程序,如:
puppetmasterd –debug
puppetca puppet认证程序,主要用于对slave的证书进行认证,如:
查看需认证的slave:puppetca –list
对这些slave进行认证:puppetca -s –a
puppetrun 用于连接客户端,强制运行本地配置文件,如:
puppetrun -p 10 –host host1 –host host2 -t remotefile -t webserver
(2) 配置文件
puppet.conf
Puppet的主配置文件,如果是root用户,配置文件为/etc/puppet/puppet.conf,普通用户,配置文件为:~user/.puppet/puppet.conf
具体配置参数,参见:
fileserver.conf
puppet文件服务器的配置文件。用path配置文件路径,allow/deny配置访问权限,具体参见:http://docs.puppetlabs.com/guides/file_serving.html
3.3 验证安装是否成功
选定一个slave与master进行验证,假设slave的host为slave00,master的host为masterhost,在slave00上输入:
puppetd –test –server servername
然后在masterhost上查看待认证的slave:
puppetca –list
如果没问题的话,此时可以看到slave00,对该slave的证书进行签名:
puppetca -s -a
这样slave00通过了证书验证,可以与master进行进一步交互了。
在masterhost的/etc/puppet/manifests目录下编写site.pp文件,内容如下:
node default {
file {
“/tmp/test”:
content=>”hello\n”,
mode => 0644;
}
}
同时在slave00上输入:puppetd –test –server servername, 查看slave00的/tmp文件夹,生成了一个新文件test,里面的内容是hello,该文件的权限是-rw-r—r—。这样,便证明puppet安装成功,如果出现错误,查看第六节。
4. 配置脚本编写
本节介绍puppet的配置脚本编写方法,主要是指puppet的manifest编写方法。puppet把需要管理的内容抽象成为资源,每种资源有不同的属性,因此puppet语言就是描述这些资源的属性以及资源之间关系的语言。
为了便于管理,puppet将资源模块化,即每个功能模块的manifest单独放在一个目录下。每个模块包含一个主要的manifest文件(init.pp,它是模块的入口,类似于C语言中的main函数),里面包含若干个class对该模块的资源进行封装,常见的资源有file,package,service等,每种资源由自己的属性,如file有属性name,owner,mode等。
本节主要介绍puppet中manifest的编写方法,将依次介绍资源属性,资源,节点管理,函数和模块的编写方法。
4.1 资源属性
资源属性有两种,一种是资源专属属性,另一种是资源共同属性,对于资源专属属性,将在下一节介绍;而资源共同属性是所有资源共有的属性,主要有:
before
用于控制不同对象(资源)的执行顺序关系,表示某个对象(资源)在另一个对象之后发生(require与之相反,它表示之前发生)。如:
file { “/var/nagios/configuration”:
source => “…”,
recurse => true,
before => Exec["nagios-rebuid"]
}
exec { “nagios-rebuild”:
command => “/usr/bin/make”,
cwd => “/var/nagios/configuration”
}
这段代码保证用make编译之前,所有代码都是最新的。也可以before多个资源,如:
before => [ File["/usr/local"], File["/usr/local/scripts"] ]
subscribe
检测某个资源,当它发生变化时,该资源会重新加载,如:
class nagios {
file { “/etc/nagios/nagios.conf”:
source => “puppet://server/module/nagios.conf”,
alias => nagconf # just to make things easier for me
}
service { nagios:
ensure => running,
subscribe => File[nagconf]
}
}
当检测到文件nagconf被修改时,服务nagios会相应的更新。需要注意的是,目前支持subscribe的资源只有exec,service和mount。
更多资料,参见:http://docs.puppetlabs.com/references/latest/metaparameter.html
4.2 资源
常用的资源主要有以下几个:
file:文件管理
package:软件包管理
service:系统服务管理
cron:配置定期任务
exec:运行shell命令
(1) file资源
更详细资料,可参见:http://puppet.wikidot.com/file
(2) package资源
更详细资料,可参见:http://puppet.wikidot.com/package
(3) service资源
更详细资料,可参见:http://puppet.wikidot.com/srv
(4) exec资源
更详细资料,可参见:http://puppet.wikidot.com/exec
(5) cron资源
更详细资料,可参见:http://puppet.wikidot.com/cron
4.3 节点管理
puppet如何区分不同的客户端,并且给不同的服务端分配manifest呢?puppet使用node资源做这件事情,node 后面跟客户端的主机名,例如:
node ‘ slave00 ‘ {
include ssh
}
node ‘ slave11 ‘ {
$networktype=”tele”
$nagioscheckport=”80,22,3306″
include apache, mysql, php
}
资源node中可使用变量,也可直接通过include把其他manifest包含进来。
更详细资料,可参见:http://docs.puppetlabs.com/references/latest/type.html
4.4 类和函数
类可以把多个相关的资源定义在一起,组成一个类。类可以继承,具体参见:http://docs.puppetlabs.com/guides/language_guide.html
函数(在puppet中称为“defination”)可以把多个资源包装成一个资源,或者把一个资源包装成一个模型,便于使用。例如,在debian里面管理一个apache虚拟机非常简单,把一个虚拟主机的配置文件放到/etc/sites-available/里面,然后做一个符号链接到/etc/sites-enabled目录。 你可以为你每个虚拟主机复制同样的配置代码,但是如果你使用下面的代码就会更好和更简单:
define virtual_host($docroot, $ip, $order = 500, $ensure = “enabled”) {
$file = “/etc/sites-available/$name.conf”
# The template fills in the docroot, ip, and name.
file { $file:
content => template(“virtual_host.erb”),
notify => Service[apache]
}
file { “/etc/sites-enabled/$order-$name.conf”:
ensure => $ensure ? {
enabled => $file,
disabled => absent
}
}
}
然后,你就可以使用这个定义来管理一个apache虚拟主机,如下面代码所示:
virtual_host { “reductivelabs.com”:
order => 100,
ip => “192.168.0.100″,
docroot => “/var/www/reductivelabs.com/htdocs”
}
4.5 模块
一个模块就是一个/etc/puppet/modules目录下面的一个目录和它的子目录,在puppet的主文件site.pp里面用import modulename可以插入模块。新版本的puppet可以自动插入/etc/puppet/modules目录下的模块。引入模块,可以结构化代码,便于分享和管理。例如关于apache的所有配置都写到apache模块下面。一个模块目录下面通常包括三个目录:files,manifests,templates。manifests 里面必须要包括一个init.pp的文件,这是该模块的初始(入口)文件,导入一个模块的时候,会从init.pp开始执行。可以把所有的代码都写到init.pp里面,也可以分成多个pp文件,init 再去包含其他文件。files目录是该模块的文件发布目录,puppet提供一个文件分发机制,类似rsync的模块。templates 目录包含erb模型文件,这个和file资源的template属性有关。
puppet安装好以后,modules目录是没有的,自己建立一个就行,然后在里面可以新增加你的模块。
5. 编程实例
5.1 Hello World
本节介绍了一个非常简单的编程实例:一个slave从master中获取其manifest,该maniftest要求slave依次做以下工作:安装gcc,创建文件夹/home/dxc/test,下载文件hello.c程序,编译hello.c。
(1) 代码结构组织
Master上代码的目录结构如下:
|– auth.conf
|– fileserver.conf #puppet文件服务器配置文件
|– manifests #puppet主文件所在目录
| |– modules.pp #puppet各个模块汇总
| |– nodes #各个slave要处理的模块
| | `– execHello.pp #hello模块对应由那些slave处理
| `– site.pp #puppet主文件(入口文件)
|– modules #puppet的各个模块所在文件
| `– hello #hello模块
| |– files #该模块对应的文件资源,可能是要发送给slave的配置文件等
| | `– hello.c
| `– manifests #模块的manifest文件
| `– init.pp #模块入口文件
`– ssl #puppet的证书文件目录
(2) 程序执行流程
代码调用顺序是:
Slave发起连接请求 à site.pp à nodes àmodules à init.pp
首先,slave向发起master连接请求,进行证书验证;
接着,证书验证通过后,master会直接找到入口文件manifests目录下的site.pp文件,该文件可能包含一些全局变量,参数缺省值(当各个模块没有设置这些参数时,它们的缺省值)以及其它pp文件的调用(在该例子中,会调用modules.pp和nodes下的各个pp文件);
然后,master通过nodes下的各个pp文件定位到该slave要执行的模块(init.pp是各个模块的入口),汇总这些模块代码返回给slave;
最后,slave根据master发过来的manifest,配置信息。
(3) 代码解释
直接在此处下载代码。
5.2 一个更复杂的实例
本节介绍了一个更为复杂的某个公司正在使用实例,puppet代码布局与上一个实例一致,只不过该实例涉及到更多模块,更复杂的依赖管理。代码具体内容本节就不解释了,具体参见代码。
6. 可能遇到的问题
Q: puppet的证书机制
A: puppet证书问题是初学者最容易遇到的问题,这里讲一下怎么处理。puppet服务器端在安装或者首次启动的时候,会自动生产一个根证书和服务器证书,证书和主机名相关,因此如果证书生成后友改了主机名,那就会出问题。 puppet客户端在首次启动的时候,也会自动生成证书;但是这个证书需要得到puppet服务器端的签名才行,因此;puppet客户端第一次连接服务器的时候,会发送一个证书请求;服务器端需要对这个证书进行签名。puppet客户端在下次连接服务器的时候就会下载签名好的证书。
Q:Ubuntu下面的证书出错,怎么解决?
A:本方法是提供给初学者的测试环境,生成环境不建议这么做。首先在puppetmaster(服务器端)删除/var/lib/puppet/ssl目录;然后启动puppetmasterd;然后在客户端也删除/var/lib/puppet/ssl目录。把puppetmaster机器的主机名和对应的ip地址写入客户端机器的/etc/hosts。
然后执行:puppetd –test –server server.example.com. 把server.example.com替
换成你自己的服务器主机名。 执行这个命令,会有提示信息,不用理会。
然后登录到puppetmaster服务器机器,执行puppetca –list 命令,看看是否有客户端的证书请求;如果没有,请检查前面的步骤是执行正确,以及网络连接是否正常。 如果puppetca –list 能看到请求,那么执行puppetca -s -a 命令;对所有的证书请求签名。最后回到puppet客户端机器,执行
puppetd –test –server server.example.com.
就能建立连接了,如果你的site.pp写好了.就可以测试puppet了。
补充:如果客户端和服务器端的时间不一致也会导致证书认证失败,因此出现证书问题的时候需要检查两台机器的时间是否一致,如果不一致用date命令或者ntpdate命令让两台机器的时间一致。
Q:出现错误[Puppet Users] err: Could not retrieve catalog; skipping run
A:可能是由于安装了两个版本的ruby或者facter的原因,解决方案见:
7. 总结
随着服务器集群规模越来越大,自动化配置和部署这些服务器能够使管理变得非常容易并大大减小管理部署成本,因而得到IT公司的高度重视。
本文档介绍了puppet,一种新型的软件自动化配置和部署工具。本文主要内容涉及puppet的架构,安装和使用方法,并给出了两个使用实例。
在大规模的生成环境中,如果只有一台puppetmaster会忙不过来的,因为puppet是用ruby写的,ruby是解析型语言,每个客户端来访问,都要解析一次,当客户端多了就忙不过来,所以需要扩展成一个服务器组。puppetmaster可以看作一个web服务器,实际上也是由ruby提供的web服务器模块来做的。因此可以利用web代理软件来配合puppetmaster做集群设置,具体参见:http://puppet.wikidot.com/puppetnginx。
8. 参考资料
puppet官方网站:http://www.puppetlabs.com/
puppet中文wiki:http://puppet.chinaec2.com/
puppet中文博客:http://www.comeonsa.com
9. 代码下载
(1)5.1节实例代码下载
(2)5.2节实例代码下载
原创文章,转载请注明:转载自董的博客



{kind=link}