win10+RTX3050ti+TensorFlow+cudn+cudnn配置深度学习环境的方法
这篇文章主要介绍了win10+RTX3050ti+TensorFlow+cudn+cudnn配置深度学习环境,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下
避坑1:RTX30系列显卡不支持cuda11.0以下版本,具体上限版本可自行查阅:
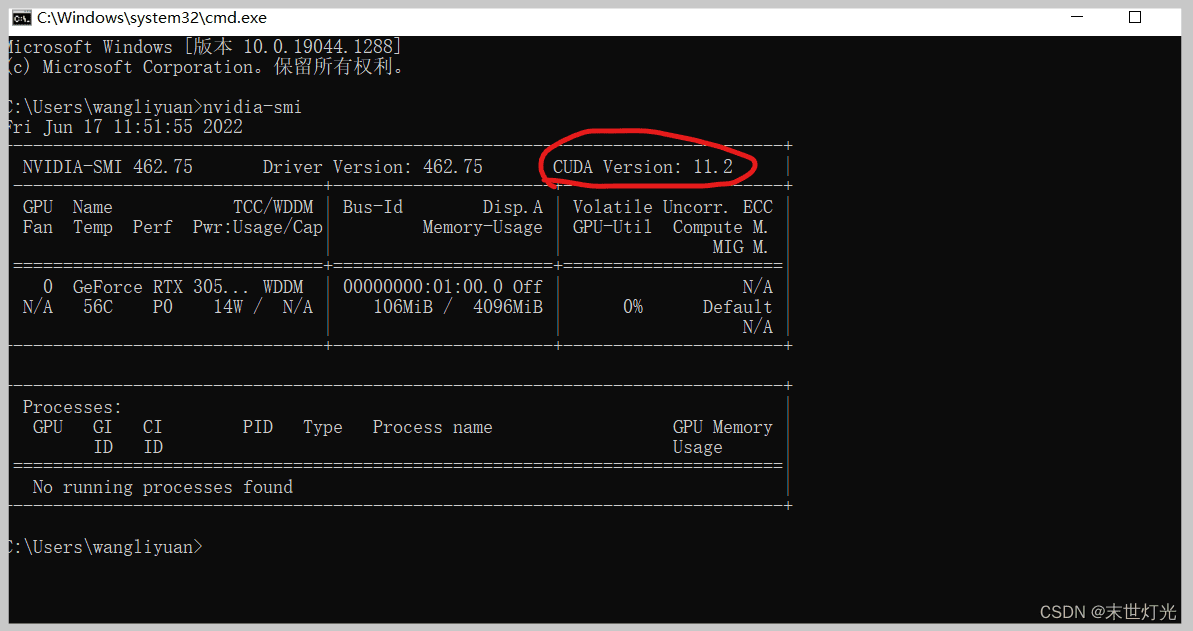
方法一,在cmd中输入nvidia-smi查看
方法二:
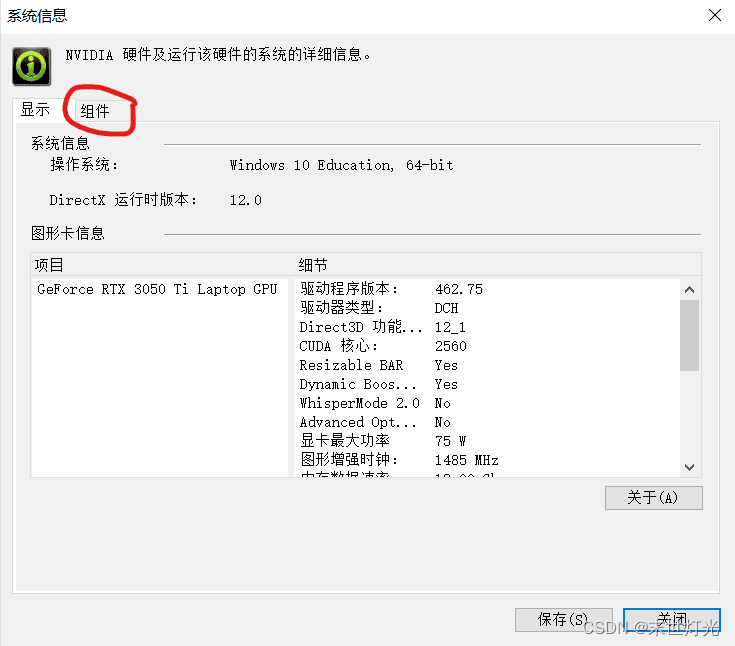
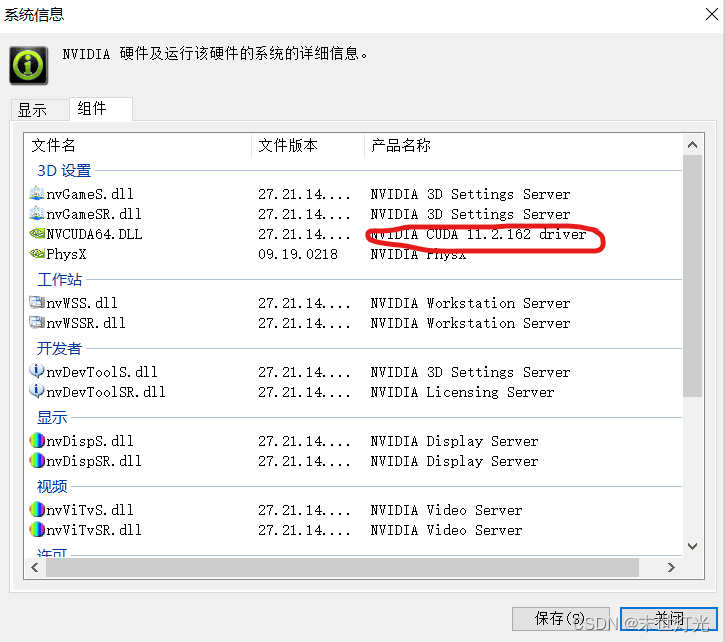
由此可以看出本电脑最高适配cuda11.2.1版本;
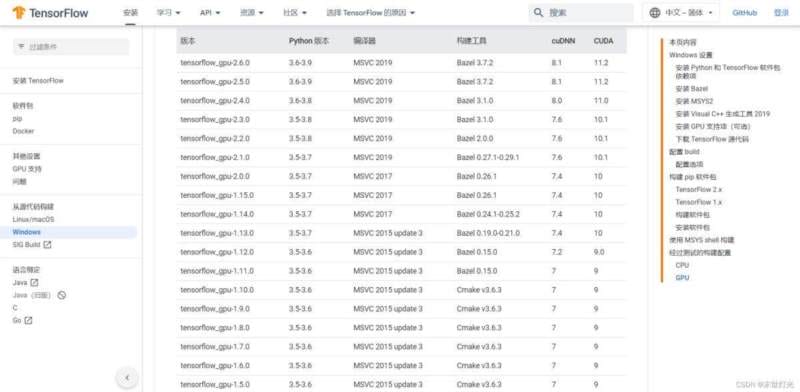
注意需要版本适配,这里我们选择TensorFlow-gpu = 2.5,cuda=11.2.1,cudnn=8.1,python3.7
接下来可以下载cudn和cundnn:
官网:https://developer.nvidia.com/cuda-toolkit-archive
下载对应版本exe文件打开默认安装就可;
验证是否安装成功:

官网:cuDNN Archive | NVIDIA Developer
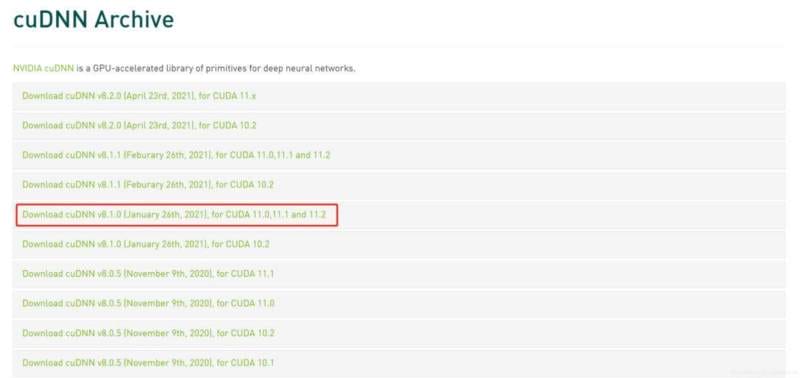
把下载文件进行解压把bin+lib+include文件复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2文件下;
进入环境变量设置(cuda会自动设置,如果没有的补全):
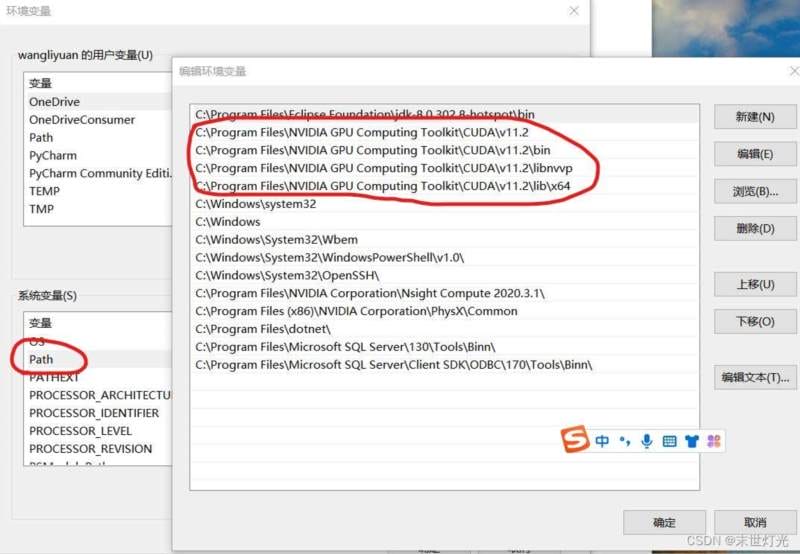
查看是否安装成功:
cd C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\extras\demo_suite bandwidthTest.exe
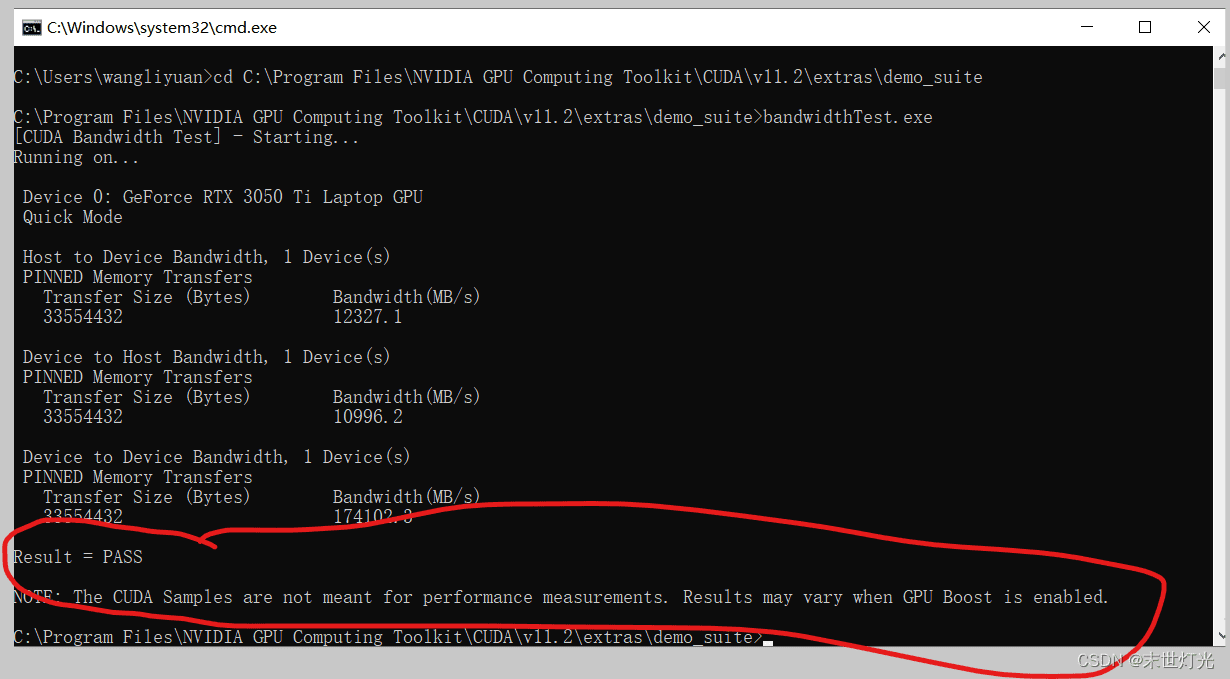
安装tensorflow-gpu:
pip install tensorflow-gpu==2.5
最后我们找相关程序来验证一下:
第一步:
import tensorflow as tf
print(tf.__version__)
print('GPU', tf.test.is_gpu_available())
第二步:
# _*_ coding=utf-8 _*_
'''
@author: crazy jums
@time: 2021-01-24 20:55
@desc: 添加描述
'''
# 指定GPU训练
import os
os.environ["CUDA_VISIBLE_DEVICES"]="0" ##表示使用GPU编号为0的GPU进行计算
import numpy as np
from tensorflow.keras.models import Sequential # 采用贯序模型
from tensorflow.keras.layers import Dense, Dropout, Conv2D, MaxPool2D, Flatten
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import TensorBoard
import time
def create_model():
model = Sequential()
model.add(Conv2D(32, (5, 5), activation='relu', input_shape=[28, 28, 1])) # 第一卷积层
model.add(Conv2D(64, (5, 5), activation='relu')) # 第二卷积层
model.add(MaxPool2D(pool_size=(2, 2))) # 池化层
model.add(Flatten()) # 平铺层
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
return model
def compile_model(model):
model.compile(loss='categorical_crossentropy', optimizer="adam", metrics=['acc'])
return model
def train_model(model, x_train, y_train, batch_size=32, epochs=10):
tbCallBack = TensorBoard(log_dir="model", histogram_freq=1, write_grads=True)
history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, shuffle=True, verbose=2,
validation_split=0.2, callbacks=[tbCallBack])
return history, model
if __name__ == "__main__":
import tensorflow as tf
print(tf.__version__)
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
(x_train, y_train), (x_test, y_test) = mnist.load_data() # mnist的数据我自己已经下载好了的
print(np.shape(x_train), np.shape(y_train), np.shape(x_test), np.shape(y_test))
x_train = np.expand_dims(x_train, axis=3)
x_test = np.expand_dims(x_test, axis=3)
y_train = to_categorical(y_train, num_classes=10)
y_test = to_categorical(y_test, num_classes=10)
print(np.shape(x_train), np.shape(y_train), np.shape(x_test), np.shape(y_test))
model = create_model()
model = compile_model(model)
print("start training")
ts = time.time()
history, model = train_model(model, x_train, y_train, epochs=2)
print("start training", time.time() - ts)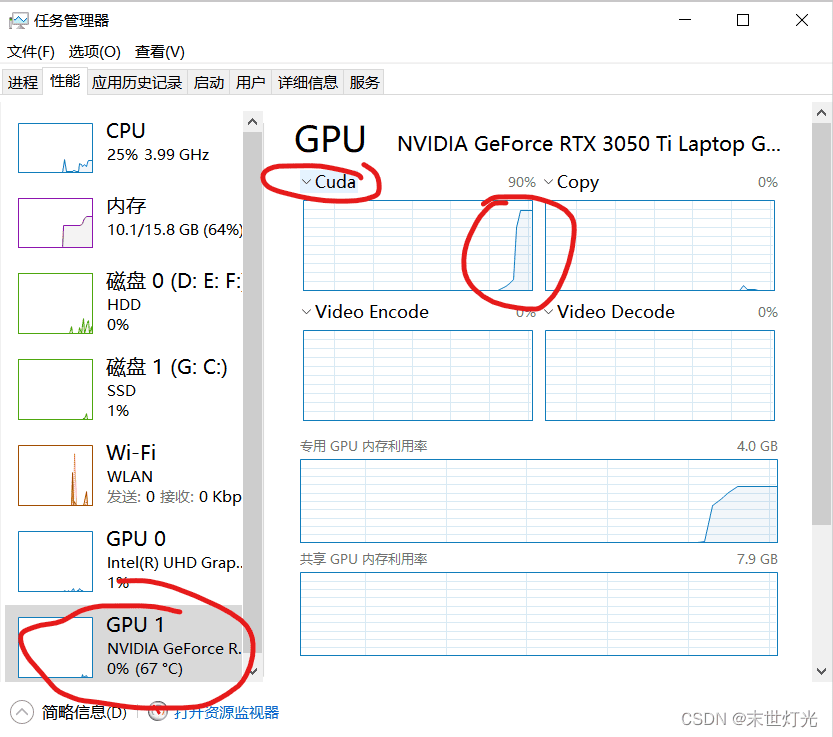
验证成功。
以上就是win10+RTX3050ti+TensorFlow+cudn+cudnn配置深度学习环境的详细内容,更多关于win10+RTX3050ti+TensorFlow+cudn+cudnn深度学习的资料请关注其它相关文章!
很赞哦!()


大图广告(830*140)
