如何使用Python 抓取和优化所有网站图像
我发布了一个通过FTP自动优化新图像的教程。这次我们将抓取整个网站,并在本地优化我们碰到的图像,按URL组织。
请注重,这个简短但中级的脚本不适用于大型站点。首先,所有图像都转储到一个文件夹中。为每个页面创建一个新文件夹并不困难,但即便如此,您也可能有数量无法治理的文件夹。未优化的图像仍旧是未通过 Web 核心指标的罪魁祸首。让我们开始!
要求和假设
已安装 Python 3 并理解基本的 Python 语法
- 访问Linux安装(我推荐Ubuntu)或宝塔
安装模块
在我们开始之前,请记住注重您在此处复制的任何内容的缩入,因为有时代码片段无法完美复制。下面的所有模块都应该在核心Python 3中。我发现我需要将 PIL 更新到最新版本 8.2,您可以通过终端中的以下命令执行此操作(假如使用 Google Colab,请在开头加上感叹号):
另外,我们需要安装 Elias Dabbas的 advertools 模块
pip3 install PIL --upgrade pip3 install advertools
- advertools:使用刮擦处理抓取
- pandas:帮助规范化爬网数据
- os:用于制作映像目录
- requests:用于下载图像
- PIL:处理图像压缩
- shutil:处理在本地保存图像
导进 Python 模块
让我们首先导进上面描述的这个脚本所需的模块。
import advertools as adv import pandas as pd import os import requests # to get image from the web import shutil # to save it locally from PIL import Image import PIL
启动网络爬网
我们需要做的第一件事是定义网络爬虫的起始 URL。99%的时间这应该是你的主页。然后我们在advertools中运行adv.crawl()函数,并将输出保存为crawl.jl,然后将其加载到crawlme数据帧中。此过程可能需要几分钟,详细取决于您的网站有多大。我不建议在页面或图像超过数万个的非常大的网站上使用此脚本。一般来说,爬虫非常快,只需几秒钟即可处理这个博客。另外,请注重,某些使用 Cloudflare 或其他防火墙的站点最终可能会在某个时候被阻止。
site_url = 'https://importsem.com'
adv.crawl(site_url, 'crawl.jl', follow_links=True)
crawlme = pd.read_json('crawl.jl', lines=True)
规范化和修剪爬网数据
使用我们的数据帧,我们可以开始规范化和修剪数据,使其仅满意我们的需要。通常有很多 nan 和空白值,因此我们删除这些行。
crawlme.dropna(how='all') crawlme.drop(crawlme[crawlme['canonical'] == 'nan'].index, inplace = True) crawlme.drop(crawlme[crawlme['img_src'] == ''].index, inplace = True) crawlme.reset_index(inplace = True)
爬网数据帧包含大量爬网数据。出于我们的目的,我们只需要规范列和img_src列。我们选择这些列并将它们转换为字典对象。
url_images = crawlme[['canonical','img_src']].to_dict()
接下来,我们设置一个计数器来帮助循环访问图像键和一个名为 dupes 的列表变量来存储我们已经处理过的图像的 URL,这样我们就不会再次处理它们。
x = 0
dupes = []
创建输出文件夹
现在我们希望创建两个文件夹。一个用于存储原始文件,以防您需要还原它们,另一个文件夹用于存储优化的图像。假如这些文件夹已经存在,它只是将路径发送到变量中。
try: path = os.getcwd() + "/images/" optpath = os.getcwd() + "/images_opt/" os.mkdir(path) os.mkdir(optpath) except: path = os.getcwd() + "/images/" optpath = os.getcwd() + "/images_opt/"
处理图像的网址
现在是时候处理 URL 了。我们遍历规范密钥中的 URL。然后我们使用计数器变量将其与img_src键匹配。每个 URL 的图像用“@@”分隔。因此,我们将img_src字符串拆分为“@@”,这变成了一个列表。
for key in url_images['canonical'].items():
print(key[1])
images = url_images['img_src'][x].split('@@')
在处理 URL 的img_src列表之前,我们希望将主页的图像 URL 预加载到重复列表中。
if x == 0:
dupes = images
流程映像
现在,只要每个图像未在重复列表中列出,我们就会对其入行处理。这确保了我们不会一遍又一遍地处理相同的图像。常见的情况是设计框架图像和徽标,可以在每个页面上找到。这些将在找到它们的第一个 URL 上处理,然后不会再次处理。我们通过反斜杠拆分字符串来获取图像文件名,然后选择创建的最后一个列表项,这将是文件名。然后使用哀求模块下载并解码文件。
for i in images:
if i not in dupes or x == 0:
filename = i.split("/")[-1]
r = requests.get(i, stream = True)
r.raw.decode_content = True
假如图像下载成功,我们将文件保存到我们之前设置的文件夹中。
if r.status_code == 200:
with open(path + filename,'wb') as f:
shutil.copyfileobj(r.raw, f)
优化图像
将图像下载到原始图像文件夹中后,我们在本地打开它并使用PIL模块对其入行处理,并将优化的输出保存在我们之前设置的优化图像文件夹中。使用质量参数。65 我通常很安全,但假如你观到图像退化,你可以把它放低或需要提高它。假如需要,您还可以选择调整图像大小。只需使用 PIL 的 Image.resize() 函数即可。文档在这里。
picture = Image.open(path + filename)
picture.save(optpath + filename, optimize=True, quality=65)
print('Image successfully downloaded and optimized: ',filename)
else:
print('Download Failed')
处理完 URL 的所有图像后,我们将处理的任何 URL 与重复列表中包含的内容入行比较。假如某个网址不在重复列表中,则会添加该网址,因此假如在另一个网址上找到该网址,我们不会再次处理该网址。
if x != 0:
[dupes.append(z) for z in images if z not in dupes]
最后,我们输出计数器入行入程跟踪,并将计数器增加 1。然后,第一个 URL 循环再次启动,并处理下一个 URL
print(x)
x += 1
示例输出
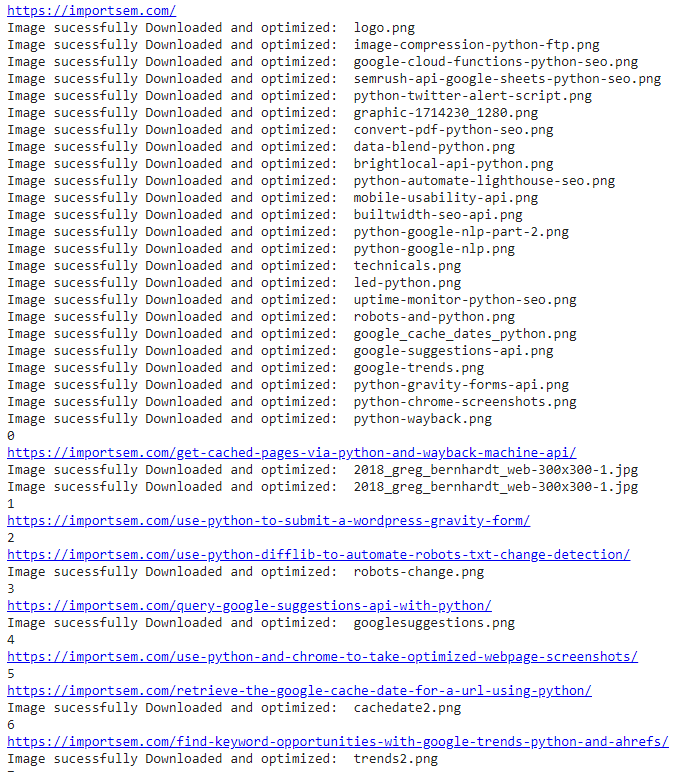
结论
有了这个,您现在可以非常快速地抓取和优化任何网站的文件。假如你有一个非常大的网站,你至少拥有构建更健壮的东西所需的框架。
到此这篇关于如何使用Python 抓取和优化所有网站图像的文章就介绍到这了,更多相关Python 抓取和优化所有网站图像内容请搜索以前的文章或继承浏览下面的相关文章希望大家以后多多支持!


