正则表达式(?=)正向先行断言实战案例
最近在训练正则表达式,碰到了一道很有意思的题,题目如下

我的答案如下
(?=.*?[A-Z])(?=.*?\d)(?=.*?[a-z]).{8,}对于这个答案的理解得先从正向先行断言的语法开始说起。
正向先行断言的语法格式如下
expression1(?=expression2) # 查找expression2前面的expression1
当然这个expression1也可以不写(也就是为空白符)
例子如下

该正则表达式的意思为:寻找abcd字符串前的123456字符串。
这里也提一个有意思的地方

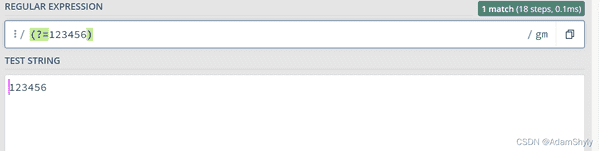
以上两个正则表达式中的/\d+/gm和/123456/gm其实都能匹配123456这个字符串,但在正向先行断言中,前者会匹配每个数字前面的空白符,后者将123456字符串当成一个整体,只匹配这个整体前面的空白符。
这里面的原理还需要等我研究一下,估计是跟底层代码的实现有关,我预测是(?=\d+)在匹配的时候会将每个数字单独提取出然后向前比较。
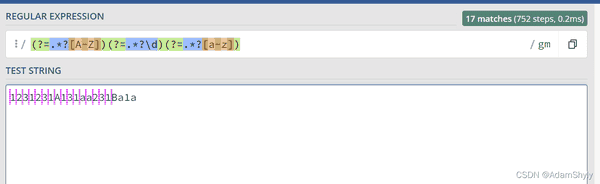
那么归到该题的答案中,先让我们观观 (?=.*?[A-z]) 是什么意思。

很明显上图匹配了大写字母A前面的所有空白符
其中的.*?[A-Z]代表大写字母及其前面的字符串且为懒惰匹配

那么(?=.*?[A-Z])(?=.*?\d)的意思就有点套娃了,按我的理解就是对于(?=.*?\d)而言把(?=.*?[A-Z])当成expression1,对于(?=.*?[A-Z])而言就是把空白符当成expression1。
那么这个正则表达式就表示为:在寻找到每个大写字母前面的所有空白符的基础上还要满意:这些空白符都在每个数字前面的所有空白符这个匹配集合中。相称于是两个空白符集合的交集。
所以(?=.*?[A-Z])(?=.*?\d)(?=.*?[a-z])相称于是每个大写字母、小写字母、数字前面的所有空白字符的交集。
而后面的.{8,}则匹配这些空白字符后面至少八位字符(贪婪匹配)。

附:先行否定断言
x(?!y)称为先行否定断言(Negative look-ahead),x只有不在y前面才匹配,y不会被计进返归结果。比如,要匹配后面跟的不是百
分号的数字,就要写成/\d+(?!%)/。
/\d+(?!\.)/.exec('3.14') // ["14"]
// ["14"]
上面代码中,正则表达式指定,只有不在小数点前面的数字才会被匹配,因此返归的结果就是14。
“先行否定断言”中,括号里的部分是不会返归的。
var m = 'abd'.match(/b(?!c)/); m // ['b']
上面的代码使用了先行否定断言,b不在c前面所以被匹配,而且括号对应的d不会被返归。
总结
到此这篇关于正则表达式(?=)正向先行断言的文章就介绍到这了,更多相关正则表达式正向先行断言内容请搜索以前的文章或继承浏览下面的相关文章希望大家以后多多支持!


