一文带你了解Golang中select的实现原理
概述
select是go提供的一种跟并发相关的语法,非常有用。本文将介绍 Go 语言中的 select 的实现原理,包括 select 的结构和常见问题、编译期间的多种优化以及运行时的执行过程。
select 是一种与 switch 非常相似的控制结构,与 switch 不同的是,select 中虽然也有多个 case,但是这些 case 中的表达式都必须与 Channel 的操作有关,也就是 Channel 的读写操作,下面的函数就铺示了一个包含从 Channel 中读取数据和向 Channel 发送数据的 select 结构:
func fibonacci(c, quit chan int) {
x, y := 0, 1
for {
select {
case c <- x:
x, y = y, x+y
case <-quit:
fmt.Println("quit")
return
}
}
}这个 select 控制结构就会等待 c <- x 或者 <-quit 两个表达式中任意一个的返归,无论哪一个返归都会连忙执行 case 中的代码,不过假如了 select 中的两个 case 同时被触发,就会随机选择一个 case 执行。
结构
select 在 Go 语言的源代码中其实不存在任何的结构体表示,但是 select 控制结构中 case 却使用了 scase 结构体来表示:
type scase struct {
c *hchan
elem unsafe.Pointer
kind uint16
pc uintptr
releasetime int64
}由于非 default 的 case 中都与 Channel 的发送和接收数据有关,所以在 scase 结构体中也包含一个 c 字段用于存储 case 中使用的 Channel,elem 是用于接收或者发送数据的变量地址、kind 表示当前 case 的种类,总共包含以下四种:
const (
caseNil = iota
caseRecv
caseSend
caseDefault
)这四种常量分别表示不同类型的 case,相信它们的命名已经能够充分帮助我们理解它们的作用了,所以在这里也不再铺开介绍了。
现象
当我们在 Go 语言中使用 select 控制结构时,其实会碰到两个非常有趣的问题,一个是 select 能在 Channel 上入行非阻塞的收发操作,另一个是 select 在碰到多个 Channel 同时响应时能够随机挑选 case 执行。
非阻塞的收发
假如一个 select 控制结构中包含一个 default 表达式,那么这个 select 并不会等待其它的 Channel 预备就绪,而是会非阻塞地读取或者写进数据:
func main() {
ch := make(chan int)
select {
case i := <-ch:
println(i)
default:
println("default")
}
}
$ go run main.go
default当我们运行上面的代码时其实也并不会阻塞当前的 Goroutine,而是会直接执行 default 条件中的内容并返归。
随机执行
另一个使用 select 碰到的情况其实就是同时有多个 case 就绪后,select 如何入行选择的问题,我们通过下面的代码可以简朴了解一下:
func main() {
ch := make(chan int)
go func() {
for range time.Tick(1 * time.Second) {
ch <- 0
}
}()
for {
select {
case <-ch:
println("case1")
case <-ch:
println("case2")
}
}
}
$ go run main.go
case1
case2
case1
case2
case2
case1
...从上述代码输出的结果中我们可以观到,select 在碰到两个 <-ch 同时响应时其实会随机选择一个 case 执行其中的表达式,我们会在这一节中介绍这一现象的实现原理。
编译
select 语句在编译期间会被转换成 OSELECT 节点,每一个 OSELECT 节点都会持有一系列的 OCASE 节点,假如 OCASE 节点的都是空的,就意味着这是一个 default 节点:
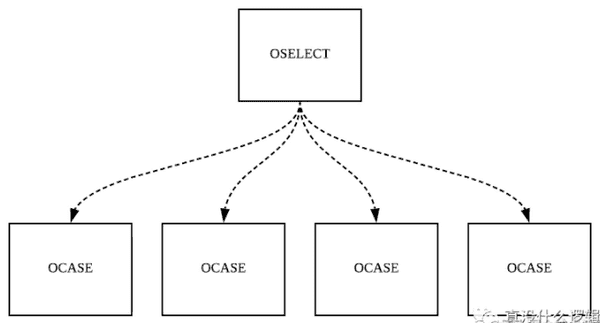
上图铺示的其实就是 select 在编译期间的结构,每一个 OCASE 既包含了执行条件也包含了满意条件后执行的代码,我们在这一节中就会介绍 select 语句在编译期间入行的优化和转换。
编译器在中间代码生成期间会根据 select 中 case 的不同对控制语句入行优化,这一过程其实都发生在 walkselectcases 函数中,我们在这里会分四种情况分别介绍优化的过程和结果:
select 中不存在任何的 case;
select 中只存在一个 case;
select 中存在两个 case,其中一个 case 是 default 语句;
通用的 select 条件;
我们会按照这四种不同的情况拆分 walkselectcases 函数并分别介绍不同场景下优化的结果。
直接阻塞
首先介绍的其实就是最简朴的情况,也就是当 select 结构中不包含任何的 case 时,编译器是如何入行处理的:
func walkselectcases(cases *Nodes) []*Node {
n := cases.Len()
if n == 0 {
return []*Node{mkcall("block", nil, nil)}
}
// ...
}这段代码非常简朴并且轻易理解,它直接将类似 select {} 的空语句,转换成对 block 函数的调用:
func block() {
gopark(nil, nil, waitReasonSelectNoCases, traceEvGoStop, 1)
}block 函数的实现非常简朴,它会运行 gopark 让出当前 Goroutine 对处理器的使用权,该 Goroutine 也会入进永久休眠的状态也没有办法被其他的 Goroutine 唤醒,我们可以观到调用 gopark 方法时传进的等待原因是 waitReasonSelectNoCases,这其实也在告诉我们一个空的 select 语句会直接阻塞当前的 Goroutine。
独立情况
假如当前的 select 条件只包含一个 case,那么就会就会执行如下的优化策略将原来的 select 语句改写成 if 条件语句,下面是在 select 中从 Channel 接受数据时被改写的情况:
select {
case v, ok <-ch:
// ...
}
if ch == nil {
block()
}
v, ok := <-ch
// ...在 walkselectcases 函数中,假如只包含一个发送的 case,那么就不会包含 v, ok := <- ch 这个表达式,因为向 Channel 发送数据并没有任何的返归值。
我们可以观到假如在 select 中仅存在一个 case,那么当 case 中处理的 Channel 是空指针时,就会发生和没有 case 的 select 语句一样的情况,也就是直接挂起当前 Goroutine 并且永遥不会被唤醒。
非阻塞操作
在下一次的优化策略执行之前,walkselectcases 函数会先将 case 中所有 Channel 都转换成指向 Channel 的地址以便于接下来的优化和通用逻辑的执行,改写之后就会入行最后一次的代码优化,触发的条件就是 — select 中包含两个 case,但是其中一个是 default,我们可以分成发送和接收两种情况介绍处理的过程。
发送
首先就是 Channel 的发送过程,也就是 case 中的表达式是 OSEND 类型,在这种情况下会使用 if/else 语句改写代码:
select {
case ch <- i:
// ...
default:
// ...
}
if selectnbsend(ch, i) {
// ...
} else {
// ...
}这里最重要的函数其实就是 selectnbsend,它的主要作用就是非阻塞地向 Channel 中发送数据,我们在 Channel 一节曾经提到过发送数据的 chansend 函数包含一个 block 参数,这个参数会决定这一次的发送是不是阻塞的:
func selectnbsend(c *hchan, elem unsafe.Pointer) (selected bool) {
return chansend(c, elem, false, getcallerpc())
}在这里我们只需要知道当前的发送过程不是阻塞的,哪怕是没有接收方、缓冲区空间不足导致失败了也会立即返归。
接收
由于从 Channel 中接收数据可能会返归一个或者两个值,所以这里的情况会比发送时稍显复杂,不过改写的套路和逻辑确是差不多的:
select {
case v <- ch: // case v, received <- ch:
// ...
default:
// ...
}
if selectnbrecv(&v, ch) { // if selectnbrecv2(&v, &received, ch) {
// ...
} else {
// ...
}返归值数量不同会导致最终使用函数的不同,两个用于非阻塞接收消息的函数 selectnbrecv 和 selectnbrecv2 其实只是对 chanrecv 返归值的处理稍有不同:
func selectnbrecv(elem unsafe.Pointer, c *hchan) (selected bool) {
selected, _ = chanrecv(c, elem, false)
return
}
func selectnbrecv2(elem unsafe.Pointer, received *bool, c *hchan) (selected bool) {
selected, *received = chanrecv(c, elem, false)
return
}因为接收方不需要,所以 selectnbrecv 会直接忽略返归的布尔值,而 selectnbrecv2 会将布尔值归传给上层;与 chansend 一样,chanrecv 也提供了一个 block 参数用于控制这一次接收是否阻塞。
通用情况
在默认的情况下,select 语句会在编译阶段经过如下过程的处理:
- 将所有的
case转换成包含 Channel 以及类型等信息的scase结构体; - 调用运行时函数
selectgo获取被选择的scase结构体索引,假如当前的scase是一个接收数据的操作,还会返归一个指示当前case是否是接收的布尔值; - 通过
for循环生成一组if语句,在语句中判定自己是不是被选中的case
一个包含三个 case 的正常 select 语句其实会被铺开成如下所示的逻辑,我们可以观到其中处理的三个部分:
selv := [3]scase{}
order := [6]uint16
for i, cas := range cases {
c := scase{}
c.kind = ...
c.elem = ...
c.c = ...
}
chosen, revcOK := selectgo(selv, order, 3)
if chosen == 0 {
// ...
break
}
if chosen == 1 {
// ...
break
}
if chosen == 2 {
// ...
break
}铺开后的 select 其实包含三部分,最开始初始化数组并转换 scase 结构体,使用 selectgo 选择执行的 case 以及最后通过 if 判定选中的情况并执行 case 中的表达式,需要注重的是这里其实也仅仅铺开了 select 控制结构,select 语句执行最重要的过程其实也是选择 case 执行的过程,这是我们在下一节运行时重点介绍的。
运行时
我们已经充分地了解了 select 在编译期间的处理过程,接下来可以铺开介绍 selectgo 函数的实现原理了。
func selectgo(cas0 *scase, order0 *uint16, ncases int) (int, bool) { } selectgo 是会在运行期间运行的函数,这个函数的主要作用就是从 select 控制结构中的多个 case 中选择一个需要执行的 case,随后的多个 if 条件语句就会根据 selectgo 的返归值执行相应的语句。
初始化
selectgo 函数首先会入行执行必要的一些初始化操作,也就是决定处理 case 的两个顺序,其中一个是 pollOrder 另一个是 lockOrder:
func selectgo(cas0 *scase, order0 *uint16, ncases int) (int, bool) {
cas1 := (*[1 << 16]scase)(unsafe.Pointer(cas0))
order1 := (*[1 << 17]uint16)(unsafe.Pointer(order0))
scases := cas1[:ncases:ncases]
pollorder := order1[:ncases:ncases]
lockorder := order1[ncases:][:ncases:ncases]
for i := range scases {
cas := &scases[i]
if cas.c == nil && cas.kind != caseDefault {
*cas = scase{}
}
}
for i := 1; i < ncases; i++ {
j := fastrandn(uint32(i + 1))
pollorder[i] = pollorder[j]
pollorder[j] = uint16(i)
}
// sort the cases by Hchan address to get the locking order.
// ...
sellock(scases, lockorder)
// ...
}Channel 的轮询顺序是通过 fastrandn 随机生成的,这其实就导致了假如多个 Channel 同时『响应』,select 会随机选择其中的一个执行;而另一个 lockOrder 就是根据 Channel 的地址确定的,根据相同的顺序锁定 Channel 能够避免死锁的发生,最后调用的 sellock 就会按照之前生成的顺序锁定所有的 Channel。
循环
当我们为 select 语句确定了轮询和锁定的顺序并锁定了所有的 Channel 之后就会开始入进 select 的主循环,查找或者等待 Channel 预备就绪,循环中会遍历所有的 case 并找到需要被唤起的 sudog 结构体,在这段循环的代码中,我们会分四种不同的情况处理 select 中的多个 case:
caseNil — 当前 case 不包含任何的 Channel,就直接会被跳过;
caseRecv — 当前 case 会从 Channel 中接收数据;
- 假如当前 Channel 的
sendq上有等待的 Goroutine 就会直接跳到recv标签所在的代码段,从 Goroutine 中获取最新发送的数据; - 假如当前 Channel 的缓冲区不为空就会跳到
bufrecv标签处从缓冲区中获取数据; - 假如当前 Channel 已经被关闭就会跳到
rclose做一些清除的收尾工作;
caseSend — 当前 case 会向 Channel 发送数据;
- 假如当前 Channel 已经被关闭就会直接跳到
rclose代码段; - 假如当前 Channel 的
recvq上有等待的 Goroutine 就会跳到send代码段向 Channel 直接发送数据;
caseDefault — 当前 case 表示默认情况,假如循环执行到了这种情况就表示前面的所有 case 都没有被执行,所以这里会直接解锁所有的 Channel 并退出 selectgo 函数,这时也就意味着当前 select 结构中的其他收发语句都是非阻塞的。
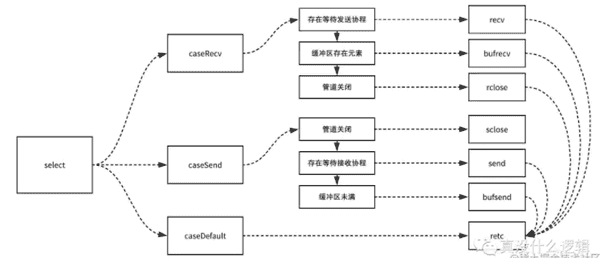
这其实是循环执行的第一次遍历,主要作用就是寻找所有 case 中 Channel 是否有可以连忙被处理的情况,无论是在包含等待的 Goroutine 还是缓冲区中存在数据,只要满意条件就会连忙处理,假如不能连忙找到活跃的 Channel 就会入进循环的下一个过程,按照需要将当前的 Goroutine 加进到所有 Channel 的 sendq 或者 recvq 队列中:
func selectgo(cas0 *scase, order0 *uint16, ncases int) (int, bool) {
// ...
gp = getg()
nextp = &gp.waiting
for _, casei := range lockorder {
casi = int(casei)
cas = &scases[casi]
if cas.kind == caseNil {
continue
}
c = cas.c
sg := acquireSudog()
sg.g = gp
sg.isSelect = true
sg.elem = cas.elem
sg.c = c
*nextp = sg
nextp = &sg.waitlink
switch cas.kind {
case caseRecv:
c.recvq.enqueue(sg)
case caseSend:
c.sendq.enqueue(sg)
}
}
gp.param = nil
gopark(selparkcommit, nil, waitReasonSelect, traceEvGoBlockSelect, 1)
// ...
}这里创建 sudog 并进队的过程其实和 Channel 中直接入行发送和接收时的过程几乎完全相同,只是除了在进队之外,这些 sudog 结构体都会被串成链表附着在当前 Goroutine 上,在进队之后会调用 gopark 函数挂起当前的 Goroutine 等待调度器的唤醒。
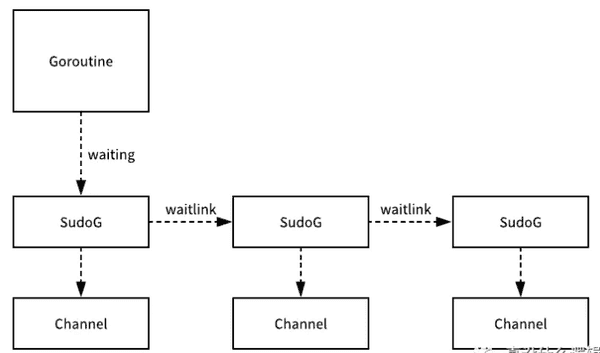
等到 select 对应的一些 Channel 预备好之后,当前 Goroutine 就会被调度器唤醒,这时就会继承执行 selectgo 函数中剩下的逻辑,也就是从上面 进队的 sudog 结构体中获取数据:
func selectgo(cas0 *scase, order0 *uint16, ncases int) (int, bool) {
// ...
gp.selectDone = 0
sg = (*sudog)(gp.param)
gp.param = nil
casi = -1
cas = nil
sglist = gp.waiting
gp.waiting = nil
for _, casei := range lockorder {
k = &scases[casei]
if sg == sglist {
casi = int(casei)
cas = k
} else {
if k.kind == caseSend {
c.sendq.dequeueSudoG(sglist)
} else {
c.recvq.dequeueSudoG(sglist)
}
}
sgnext = sglist.waitlink
sglist.waitlink = nil
releaseSudog(sglist)
sglist = sgnext
}
c = cas.c
if cas.kind == caseRecv {
recvOK = true
}
selunlock(scases, lockorder)
goto retc
// ...
}在第三次根据 lockOrder 遍历全部 case 的过程中,我们会先获取 Goroutine 接收到的参数 param,这个参数其实就是被唤醒的 sudog 结构,我们会依次对比所有 case 对应的 sudog 结构找到被唤醒的 case 并释放其他未被使用的 sudog 结构。
由于当前的 select 结构已经挑选了其中的一个 case 入行执行,那么剩下 case 中没有被用到的 sudog 其实就会直接忽略并且释放掉了,为了不影响 Channel 的正常使用,我们还是需要将这些废弃的 sudog 从 Channel 中出队;而除此之外的发生事件导致我们被唤醒的 sudog 结构已经在 Channel 入行收发时就已经出队了,不需要我们再次处理,出队的代码以及相关分析其实都在 Channel 一节中发送和接收的章节。
当我们在循环中发现缓冲区中有元素或者缓冲区未满时就会通过 goto 要害字跳转到以下的两个代码段,这两段代码的执行过程其实都非常简朴,都只是向 Channel 中发送或者从缓冲区中直接获取新的数据:
bufrecv:
recvOK = true
qp = chanbuf(c, c.recvx)
if cas.elem != nil {
typedmemmove(c.elemtype, cas.elem, qp)
}
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
selunlock(scases, lockorder)
goto retc
bufsend:
typedmemmove(c.elemtype, chanbuf(c, c.sendx), cas.elem)
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
selunlock(scases, lockorder)
goto retc这里在缓冲区中入行的操作和直接对 Channel 调用 chansend 和 chanrecv 入行收发的过程差不多,执行结束之后就会直接跳到 retc 字段。
两个直接收发的情况,其实也就是调用 Channel 运行时的两个方法 send 和 recv,这两个方法会直接操作对应的 Channel:
recv:
recv(c, sg, cas.elem, func() { selunlock(scases, lockorder) }, 2)
recvOK = true
goto retc
send:
send(c, sg, cas.elem, func() { selunlock(scases, lockorder) }, 2)
goto retc不过当发送或者接收时,情况就轻微有一点复杂了,从一个关闭 Channel 中接收数据会直接清除 Channel 中的相关内容,而向一个关闭的 Channel 发送数据就会直接 panic 造成程序崩溃:
rclose:
selunlock(scases, lockorder)
recvOK = false
if cas.elem != nil {
typedmemclr(c.elemtype, cas.elem)
}
goto retc
sclose:
selunlock(scases, lockorder)
panic(plainError("send on closed channel"))
总体来观,Channel 相关的收发操作和上一节 Channel 实现原理中介绍的没有太多出进,只是由于 select 多出了 default 要害字所以会出现非阻塞收发的情况。
总结
到这一节的最后我们需要总结一下,select 结构的执行过程与实现原理,首先在编译期间,Go 语言会对 select 语句入行优化,以下是根据 select 中语句的不同选择了不同的优化路径:
空的 select 语句会被直接转换成 block 函数的调用,直接挂起当前 Goroutine;
假如 select 语句中只包含一个 case,就会被转换成 if ch == nil { block }; n; 表达式;
- 首先判定操作的 Channel 是不是空的;
- 然后执行
case结构中的内容;
假如 select 语句中只包含两个 case 并且其中一个是 default,那么 Channel 和接收和发送操作都会使用 selectnbrecv 和 selectnbsend 非阻塞地执行接收和发送操作;
在默认情况下会通过 selectgo 函数选择需要执行的 case 并通过多个 if 语句执行 case 中的表达式;
在编译器已经对 select 语句入行优化之后,Go 语言会在运行时执行编译期间铺开的 selectgo 函数,这个函数会按照以下的过程执行:
1.随机生成一个遍历的轮询顺序 pollOrder 并根据 Channel 地址生成一个用于遍历的锁定顺序 lockOrder;
2.根据 pollOrder 遍历所有的 case 查观是否有可以连忙处理的 Channel 消息;
- 假如有消息就直接获取
case对应的索引并返归; - 假如没有消息就会创建
sudog结构体,将当前 Goroutine 加进到所有相关 Channel 的sendq和recvq队列中并调用gopark触发调度器的调度;
3.当调度器唤醒当前 Goroutine 时就会再次按照 lockOrder 遍历所有的 case,从中查找需要被处理的 sudog 结构并返归对应的索引;
然而并不是所有的 select 控制结构都会走到 selectgo 上,很多情况都会被直接优化掉,没有机会调用 selectgo 函数。
Go 语言中的 select 要害字与 IO 多路复用中的 select、epoll 等函数非常相似,不但 Channel 的收发操作与等待 IO 的读写能找到这种一一对应的关系,这两者的作用也非常相似;总的来说,select 要害字的实现原理稍显复杂,与 Channel 的关系非常紧密,这里省略了很多 Channel 操作的细节,数据结构一章其实就介绍了 Channel 收发的相关细节。
到此这篇关于一文带你了解Golang中select的实现原理的文章就介绍到这了,更多相关Golang select内容请搜索以前的文章或继承浏览下面的相关文章希望大家以后多多支持!


